


The Importance of Complete Content Metadata
As I explore more of the full capabilities of enterprise CMS, eCommerce, and DAM solutions, it came to my attention that an underlying (no pun intended) level of detail is often incomplete or missing altogether. This detail is called content metadata, and it’s key to getting more value from all of these platforms.
What is Content Metadata?

Content metadata is all the descriptions or attributes of the content itself, whether it be a webpage, image, product listing, video, audio, or other pieces of content that are stored in centralized repositories within these enterprise solutions. These solutions then allow for the interchangeable use of these individually stored content chunks for different experiences – be it on a traditional webpage, mobile, tv or other digital destinations.
Some people or teams may create these experiences and manually insert these content components. Alternatively, the details of these stored content chunks may also be called upon dynamically depending on user engagement or other functions. For example, variables in URL query strings can pass information for dynamic content to be inserted into the digital experience. This may not require query strings; in these cases, information is passed directly to the digital experience at the data layer to transform the presentation layer.
You may be wondering, ‘how does missing metadata really impact my customer’s experience or bottom-line for that matter?’
5 ways missing metadata is detrimental to your marketing and sales efforts:
- Lack of complete indexing and findability in your enterprise search functionality
- Decreased visibility and key information available on external search engines and social platforms
- Poor accessibility for people with disabilities1
- Sub-optimal display of content within your own managed digital experiences
- Lost opportunities within recommendation engines and dynamic related content

Let me elaborate:
Lack of complete indexing and findability in your enterprise search functionality
Your search functionality could be a combination of filters and open-text search. It could be more complex like this to start:
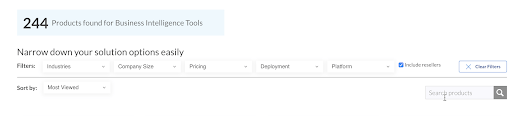
Or start as a basic search tool like this one:![]()
Entering text into that search bar leads to a more complex faceted search: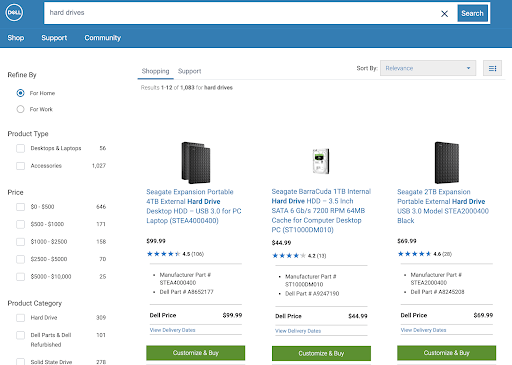
Or it could simply be a more traditional search function that results in basic search engine result page list like so: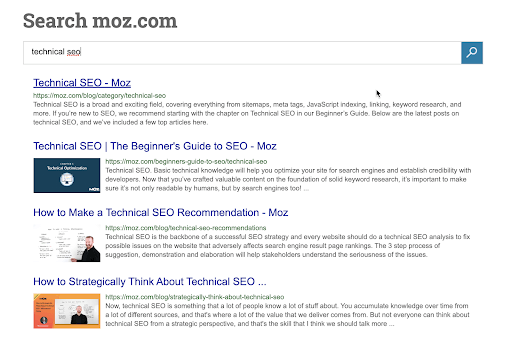
All of these search functions require metadata for displaying contextual results.
The Moz.com example is basic: Title Tag, Featured Image, URL/slug, Description and perhaps, Keywords.
Note: Keywords are debatable here because the search function probably searches within the content and metadata available, and not specifically within a Keyword field that has its own metadata values.
While their metadata is possibly more extensive, that’s all that is utilized in the display of their search results.
The other examples above (filters and faceted search) leverage much more extensive metadata values to deliver the search results. Each selector has values. Those values must exist as respective metadata values on the corresponding objects being displayed in search. In this case, product listings for both search examples I shared as screenshots above.
If this metadata is missing or incomplete for a product listing or other type of object/record, it may not be displayed in the search results.
Fortunately, I’ve worked directly in the underlying CMS for one of the previous examples. I can tell you first hand that editing those records and metadata was done one record at a time. There’s no mass data management process to easily edit them or data governance (e.g., alerts or flags) to ensure that each object has the minimum desired metadata for listing. This is a great example of the need for a strong content operations process.
Case in point:
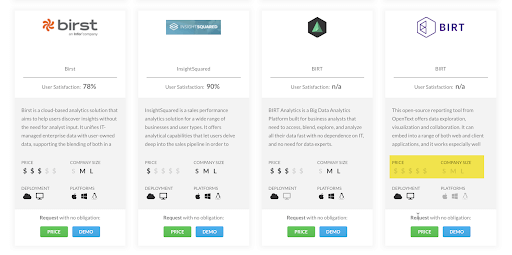
Who knows – maybe Birt is free – but there’s no filter in the Price drop-down to show that.
If someone searches for a single $ in the filter, Birt would be absent even if it is a free tool. The cause: missing metadata, or an incomplete filter selection (but that’s also a missing metadata issue).
In the example above, it’s possible that the listed vendors in this directory are paying to be there or pay to get leads who request demo requests or price inquiries. If that’s the case and metadata is missing, not showing up for key filter selections or searches could represent a lot of money lost for both parties. There’s also lost sales to account here — I can almost guarantee that using the search and filter function in that directory is a key indicator that someone is shopping for technology…
The same is likely true for the other example. Someone searching for hard drives directly on a vendor’s site is a high indicator of a purchase decision. If a key product doesn’t show because it’s missing metadata, the omission could cause significant loss in sales as well:
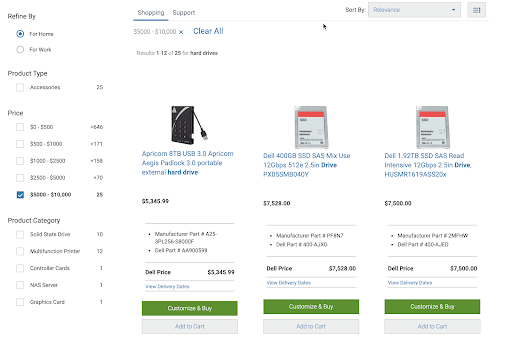
It’s clear that missing metadata can create serious issues with your search functionality, directly affecting sales and revenue.
Decreased visibility and key information available on external search engines and social platforms
Considering the examples above, if you have some familiarity with schema.org or the social graph (Graph API link), the metadata for those objects (and lots of other objects) is just as critical.
Not to get too technical, there is an object called ‘Product’ specifically noted by Schema.org standards, and it has a variety of properties. These properties require values to be used (obviously) and they are marked up in specific ways on a webpage to identify the property/value (see the Microdata tab example on the page linked above and in the screenshot below for how this markup looks).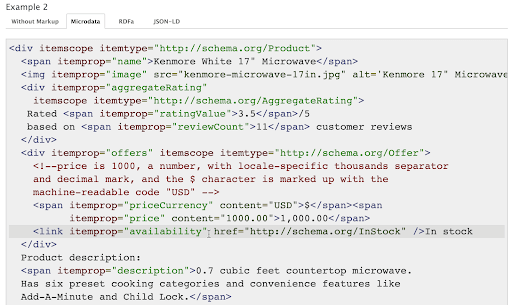
By marking up products in this way, you’re providing 3rd party sites e.g., Google, very specific and structured data about the product that can be utilized in search results.
“Many applications from Google, Microsoft, Pinterest, Yandex, and others already use these vocabularies to power rich, extensible experiences.”2
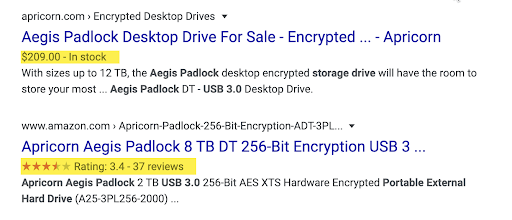
If done right, your site might get additional mark-up in the SERPs itself. Here’s an example of both price and aggregate Rating:
If you don’t mark-up properly, you might not as easily stand out to searchers:
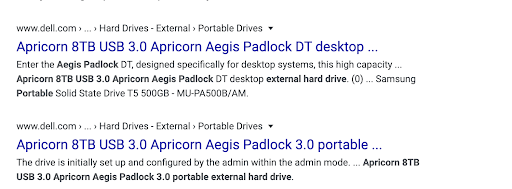
And, if you’ve worked in SEO, you know how lucrative a high position and strong click-through rate can be for generating sales. Taking advantage of metadata that creates these call-outs should be standard in your publishing flow.
Here’s an example template on how this SEO metadata (e.g., Title, Keyword, Category) could be managed in bulk across teams that have larger scale content production:
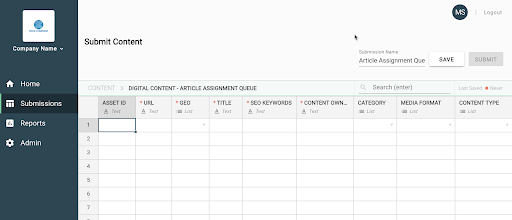
This template makes sure that key metadata for various content assets gets populated prior to being input into a DAM or CMS.
Poor accessibility for people with disabilities
Building great digital experiences for all audiences is a difficult process. Delivering one for people with disabilities requires additional care and attention, especially with metadata. I don’t know if you’ve ever reviewed the WCAG guidelines but if you didn’t think site metadata was important before, this will be eye-opening.
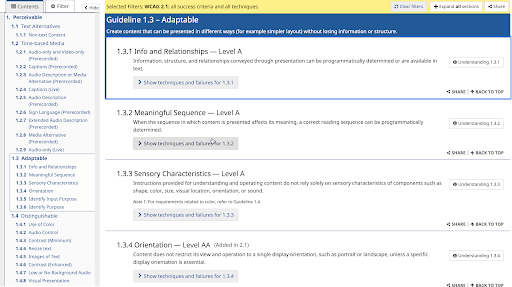
Consider alone the section entitled “Perceivables”. Each one of those main sections, Text Alternatives, Time-based Media, Adaptable and Distinguishable, are content objects (or subsets of them) that require significant metadata to be certifiably accessible.
Additionally, section 1.3, Adaptable, has a unit on Info and Relationships, with a library of mark-up and other attributes required to meet the Adaptable criteria.
I don’t mean to alarm or create more work for you, but I want to illustrate with this lawsuit related to not adhering to similar site accessibility standards:
“The National Federation of the Blind, et al. v. Target Corporation set a precedent in 2008 when it agreed to settle a lawsuit alleging that its website was not accessible to the blind, agreeing to improve the website and pay $6 million into a “Damages Fund” for members of the class-action lawsuit. The court also awarded about $3.7 million in attorney fees.”3
As digital experiences proliferate in nearly every area of our life, we need to provide great experiences for all audiences, echoing The Internet Society’s guiding principle that “‘the Internet is for Everyone’. This includes the estimated one billion people with disabilities across the world.”
I’ve been developing digital content for 20 years and have delivered many incomplete experiences in this regard. As I research and write this for you, I am taking it to heart just the same.
Just recently, in fact, I attempted to make a virtual event a little more accessible and realized that I cut corners by using automated caption generation, aka “craptions” to some in the ADA crowd. It’s a complex effort and requires thoroughness to get these standards – even beyond just the standards – right.
Sub-optimal display/presentation of rich media within your own managed digital experiences
How many screen sizes, device types, or other digital engagement platforms are out there right now? Further, how many variants and components can you have in a collection of dynamic content and rich media?
I don’t even know the answer and they seem more like philosophical conundrums than digital marketing problems.
But, the answer for some large enterprises is essentially infinite. Remember factorials in middle school math? Rich media combinations lead to that…
Imagine the following for ad variants:
9 headlines
8 descriptions
7 images
6 ad sizes (e.g. 300×250)
5 layouts
4 CTAs
3 color schemes
2 landing pages
1 campaign goal
For fun, let’s say we are running these ad variants in 10 different channels (it’s feasible)…
I’m pretty sure the math here is 10 x 9 x 8 x 7 x 6 x 5 x 4 x 3 x 2 x 1
I’ll wait and let you do the math. Hint, it’s also 10 factorial (remember good old 10!)
Yes, that’s 3 million six hundred twenty-eight thousand and eight hundred ad combinations.
3,628,800.
A highly exaggerated scenario, but enterprise digital marketing and advertising professionals can likely relate to this.
Nevertheless, that’s an example of the potential for scale on rich media. I could write a lot more on this topic, but for now, this (maybe extreme) example also conveys the magnitude of possible error when rich media metadata is incomplete or not present.
By the way, here’s a big list of rich media ad types for you to consider as you think more about the challenge and opportunity of metadata creation and management.
For another use case, what about the growing spread of smart speakers? It might not be something you’re actively creating metadata for, but it’s a huge opportunity.
This interesting whitepaper, “Mastering Metadata in the Era of Smart Speakers: Optimizing Music Discovery and Reach for Artists and Listeners,” has a great take on the value of metadata for music discovery.
“Companies that take the initiative to create robust strategies around their metadata management (MDM) will have a distinct advantage, from their customer experience to their revenue streams. Those that do not won’t just miss out on the benefits of MDM; they’ll quickly become irrelevant.”
Lost opportunities within recommendation engines and dynamic related content
If you have a site that uses a recommendation engine for displaying alternative or upsell products, or some other type of dynamic content (e.g., knowledgebase articles, location-based information, multimedia recommendations), missing metadata can cost your business in multiple ways.
Here are two prime examples:
1. You could be losing out on increased add-to-cart and checkout conversion values. If a product in your database does not have thorough metadata, it may not get associated properly with a respective complementary product. Think Amazon…who else would you think about that does an e-commerce recommendation engine better than them? Amazon’s product catalog is rich with metadata. In fact, I’m going there now to check something, hold on a sec…
Ok, I’m back.
Lesson 1 – Don’t “View Source” on an Amazon product listing – that’s a lot of code. But there’s a duck that meows at the end so that was fun.
Lesson 2 – There is a variety of metadata to consider to execute the way Amazon does. For example, metadata on the product listing itself. There’s also metadata about me, the shopper, e.g., that I already bought a book (in this case “Start With Why”) one time previously and the specific date I bought it. I also noticed that there is metadata on the various sellers of this particular book. These are visible sections/details on the product page.
There’s likely a lot going on behind the scenes like semantic content analysis that matches up with respective content and displays other recommendations. Also, there’s implicit behavioral site data collected (vs. explicit data entry like searches, add to carts, checkouts).
Lesson 3 – This metadata is a mix of dynamic creation and manual entry, yet it all has to map and associate properly in a relational database. The building of that outline or taxonomy, associating objects, and defining the attributes of each is an important yet daunting task.
2. Your engagement rates may be less than what’s possible. If you’re a content publisher (who isn’t these days), and you’re not displaying key complementary content to your users, you’re preventing them from lingering longer in your content ecosystem. Think Netflix (I believe they also miss lots of ways to display corresponding content). It might be more of an interface issue vs. just metadata but, nevertheless, even the best have this problem.
For example, I don’t think the same movie recommendation should show up in 4 different rows in my Roku Netflix experience.
Perhaps metadata around all the recommendation categories the video is in (which I’m also certain they have) paired with the current recommendation categories being displayed in my experience. Netflix could then suppress that title from showing in a recommendation category if the title visibility is >= 2. Just a thought…
Here’s a good article that expounds on this topic outlining dynamic content examples that also emphasize metadata (they call it rich data).
How to Fix your Content Metadata?
Maybe you’ve incorrectly entered or missed creating some of this metadata and are delivering less than ideal user experiences, launched sub-par campaigns, lost sales, or lack search visibility.
Aside from an initial metadata audit (maybe you started checking things here and there while reading this article), maximizing the value of all these systems that rely on metadata begins with outlining all the areas or objects that require metadata. Your next big task is to create a taxonomy and/or flowchart for these systems. Next, you’ll define and agree on a standard process to create and manage all of this metadata. This is going to require cross-functional collaboration throughout your marketing organization and beyond.
Note: while you’re doing the audit, creating taxonomies and flowcharts, and defining processes, start evaluating tools to support your metadata management efforts. We’ll mention here that if you’re already missing valuable data, an AI solution… won’t be your solution. Once people curate this information, your machines will become better (with your brand and consumer experience!)
Keep a data-driven content strategy in the back of your mind while doing your audits and planning – this should help inform you how to prioritize and tackle what is likely going to be a long to-do list.
Check out our “Strategic Guide to DAM Metadata” for more insights on this issue.
About the Author
 Michael Shearer has been fortunate to work in the digital field for more than 20 years – with an expansive career in digital marketing, analytics, operations and more. He is currently the Head of Digital Marketing at Claravine. He has written articles for a number of online publications including MarketingLand, Search Engine Land, Spin Sucks, Relevance and more. He holds advanced degrees in Information Systems and Management from Drake University and American Public University. Michael resides in Colorful Colorado with his wife and 5 children.
Michael Shearer has been fortunate to work in the digital field for more than 20 years – with an expansive career in digital marketing, analytics, operations and more. He is currently the Head of Digital Marketing at Claravine. He has written articles for a number of online publications including MarketingLand, Search Engine Land, Spin Sucks, Relevance and more. He holds advanced degrees in Information Systems and Management from Drake University and American Public University. Michael resides in Colorful Colorado with his wife and 5 children.