


Conquering Data Sprawl, the Hidden Danger of SaaS Sprawl

SaaS sprawl, the unstoppable snowball of more and more tools at an enterprise’s disposal, underscores an even more important, foundational concept: data sprawl.
Data sprawl threatens to upend your ability to get the most value from your tools (we’re talking ROI) and to collaborate effectively across departments, regions, and partners.
Unchecked data sprawl threatens the very core of your data-driven organization.
Proactive leaders across the enterprise data spectrum look to data standards as the cornerstone of fully utilized data, no matter the extent of the sprawl.
Here’s how to combat — nay, embrace — SaaS sprawl and its accompanying, and even more prescient, data sprawl.
Data sprawl, if left unchecked, will lead enterprises to miss out on the value of their SaaS, hamstring talented teams, and degrade the accuracy of data-derived insights (which is, let’s be real, all of them). It also threatens the value and security of your data center itself.

Careful data sprawl management isn’t easy, but it is accessible.
A Refresher on SaaS Sprawl
TechCrunch explains that SaaS sprawl is much more than the hundreds of apps (and more every day) deployed by large organizations (700-3,000 employees). The sprawl in SaaS tools is only the tip of the iceberg — as TechCrunch aptly visualizes as a SaaS-berg.

The author breaks the sprawl down into a few categories representing larger and larger, deeper and deeper layers of software-service expansion and IT touchpoints:
- Service sprawl — the ever-growing stack of tech tools used by enterprises for marketing, content, analytics, data science, and more.
- Identity sprawl — the number of unique identities accessing company SaaS was found to be 3 to 18 times employee headcount.
- Account sprawl — the number of distinct accounts created to use company Saas was generally found to be 10-30% higher than even the identity sprawl stated above (including a “dangerously high proportion” of administrator-level “service accounts.”
- Policy assignment sprawl — the amount of asset-level specifications made on who can access which assets (documents, data, objects, etc.) within SaaS apps.
There’s plenty to dig into: the complexity and security risks of these sprawls; the need to track and curb sprawl to protect “proprietary knowledge and sensitive information”; and the importance of multi-layer authentication for SaaS access.
All very, very important and timely points.
But, what’s beyond that iceberg?
Something all-encompassing, even huger than the SaaS sprawl that could sink the Titanic.

If SaaS sprawl is an iceberg, data sprawl is a glacier.
What is Data Sprawl?
Data sprawl is the proliferation in the number and different kinds of digital information (data) created, collected, stored, shared, and analyzed by businesses, primarily at the enterprise level.
Data sprawl has been happening for decades, as companies capture even the most mundane customer information online (think of an ecommerce purchase in the early 2000s, and the corresponding “thank you” email you got — without being followed across social media). But, it has been amplified by SaaS sprawl.
Primarily within businesses (but also extending to consumer apps), the amount of data collected on digital users, activities, interactions, processes, transactions, and more have created an unending expansion — sprawl — of enterprise data.
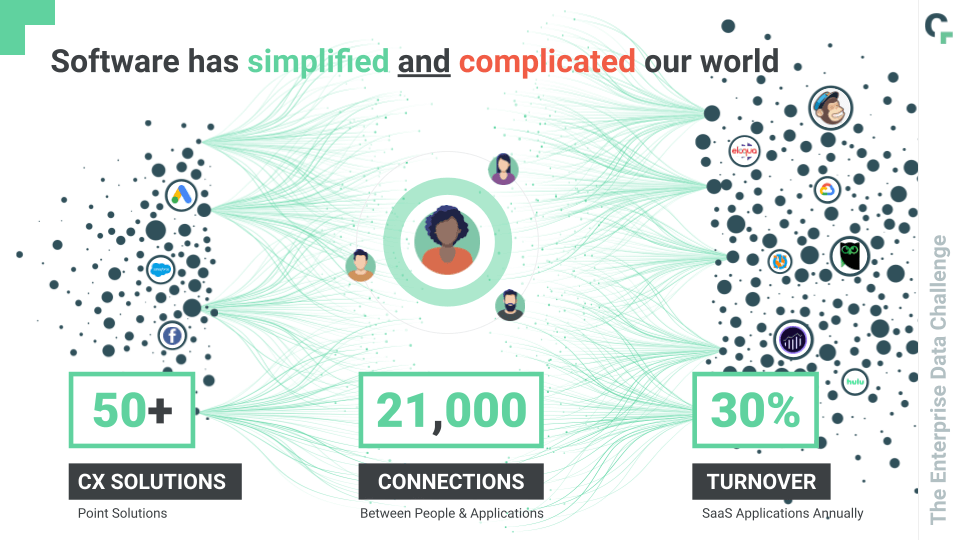
Data sprawl presents unique challenges to data management, data warehouses, and even the data sources themselves. And with the rising cost and complexity of protecting against a data breach, data sprawl only compounds the issue.
The Dangers of Data Sprawl
Consider this: companies are spending roughly 50% more on SaaS year over year (2020) with a 30% increase in unique apps in use — but they also churn through 30% of their SaaS.
SaaS “waste” saw a 100% year-over-year increase in 2020. Orphaned, duplicate, under-utilized, and mismatched SaaS costs a company not only in the unnecessary subscription fees, but also in the quality and usability of the data collected, created, and shared by those apps.
With more SaaS in use, at a higher cost and turnover, with massive inefficiencies, the enterprise’s sprawling data is crucially at risk of degradation, misplacement, and inaccessibility.
For what good is a global, million-dollar, cross-departmental tech stack if it’s not enriching both the levels of quality and access — and squeezing the most out of — the data it’s stashing in the data warehouse?
Hundreds — possibly more than a thousand — of SaaS apps in use by tens of thousands of employees means the potential for hundreds of thousands of data definitions. The way data is structured, collected, analyzed, and shared in and between these apps and users isn’t inherently the same. In fact, it’s inherently mismatched and cross-functionally useless.
The danger of data sprawl lies in uninitiated data standards.
Imagine a sales team of thousands charging off into the marketplace with a thousand different scripts. A marketing team launching disparate messaging in different regions (some of which was already tested and failed by one of those teams). Analytics teams spending more time on cleaning and organizing data than they do drawing insights. Creative teams and agencies lost in portfolios and duplicating costly assets.
As teams within enterprises collect and create more and more data via more and more SaaS, they risk working with different data “languages” defined by their distinct and disconnected apps. This handicaps and siloes — counterintuitively to what one would expect from more and more data — instead of connects and amplifies.
And that’s even before data reaches the stage of business intelligence, which is completely derailed (and approaching a well-funded shot in the dark) if data integrity, consistency, and standards are lacking.

When enterprise teams work in data siloes without data standards (and the collaboration and enrichment that comes with them), they face these common, costly challenges:
- Duplicating, wasting, and misplacing content, creative, ad, and marketing assets
- Bottlenecks as assets and projects move between teams, tools, and platforms
- Activation errors and wasted spend due to audience targeting errors and improper content alignment
- Inability to track performance with accuracy or efficiency — let alone trustworthiness — to really understand what does/doesn’t work
- Delayed insights with reduced value due to tardiness
- Incomplete data that leads to less-than-certain data-driven decisions
- Time wasted on data cleanup, hunting, and fixing instead of actual work or billable hours
- Misappropriation of budgets due to inaccurate insights caused by poor data quality
In essence, unchecked data sprawl leads to immense amounts of wasted efforts, time, budget, and infrastructure. The most pressing business risks come in the form of diminished ROI and unrealized talent/team/tactical potential.
(Data & SaaS) Sprawling Successfully
Wouldn’t it be nice if you could get the insights you needed, even if the data came from a different SaaS, team, or region? If you could trust, understand, find, and use data you had no part in collecting?
Data sprawl is inevitable, but you can embrace it and turn it into one of the sharpest tools in your shed.
At the core of your effort, remember: you need not let the SaaS you use dictate how you operate. You (and your teams) can set high-quality, cross-functional data standards that hook a strong leash to every data point — and open it up to enrichment, connection, and collaboration.
When all your SaaS apps + all your teams + all your agencies and partners communicate properly, in the same language, you can sprawl successfully.
Articulating Your Data Language
Data-driven enterprises can’t approach and conquer data sprawl without data standards that ensure data integrity.
Every app will do its data thing the way it wants to. If you get lucky, you have integrations and consistencies, but most companies are just at the behest of the regular setup and trying to manage and align with spreadsheets, or other manual approaches.
But with a data standards platform, the building and managing of data is centralized. From this, the full set of SaaS (and the teams who use them) can work more effectively — together.
When data and metadata requirements can be identified and enforced, or governed, then data, SaaS, teams, and partners can all play nicely — together.
Consider a centuries-old example of data standards: a mailing address.
Would you send out a package with an address looking like this?
Illinois, Main Street
Jim Smith of Chicago
1234, 60657
Or do you adhere to the USPS data standards regarding postal addresses and do something more like this?
Jim Smith
1234 Main St.
Chicago, IL 60657
Sure, a human could manually decipher the first address. But will they? Do they have time? And when this data enters an environment with thousands of other addresses, how would they be sorted?
Enacting data standards is the way to articulate your enterprise’s data language so that any and every piece of data collected — from a piece of content, or a campaign, or an ecommerce purchase, or a website interaction — is available and understandable to everyone in the organization. Even more, that data can be actively and passively enriched to a level never experienced before data standards.
The first step in a data standards platform’s workflow is to define and govern data/metadata format. The data standards platform can then be connected to SaaS, and begin to talk back and forth with data creators, sharers, extractors, and analyzers.
Using Data Standards to Connect Sprawling Data
Understand this: it’s absolutely crucial to enact data standards when and where data is created to effectively combat data sprawl and successfully leverage it for maximum business value.
With a common language, data is suddenly much more consistent, comparable, and usable. And this common language can include specific keys that help you to not only compare data sets but connect them. A single key can unlock data between SaaS, helping apps not only talk to each other and enrich each other’s data — but allowing other teams (with other apps) to tap into the same rich data without having to transform it into their own apps’ languages.
Defining these keys as core IDs within a data standards platform, complete and accepting of the predefined and governed metadata, provides unbreakable structured data to all your apps. Instead of trying to rectify, transform, and match disparate IDs from different SaaS, they can all root down to core IDs that tie together the metadata appended by every connected app.
Suddenly, one piece of data from one app is no longer siloed, but connected to and enriched by the corresponding data from another app.
Now, repeat this thinking throughout the hundreds of apps and thousands of employees — and millions upon millions of sprawling data sets. Instead of thousands of variations on what is essentially the same data, you now have singular data with enrichment provided by previously disparate tools.
Rich, usable, accessible, and connected data standards will amplify the ROI of team, tech, and creative investments. When something as crucial, yet mundane, as a campaign code key is built in a data standards platform, like The Data Standards Cloud, and then pushed out (and back in, around, through…) to the enterprise’s systems, you unlock consistent data representation across tools and throughout the organization.
Imagine enabling all the goals and requirements of every SaaS tool, from one place.
Truly and accurately representing data across platforms and projects to unlock more, better data-driven opportunities — that’s why future-thinking organizations enforce data standards as data sprawls.
Figure 1 represents existing data sets, disparate and differently defined. Valuable to its originating teams, yet inaccessible and functionally useless to anyone else. They’re also lacking in depth, siloed to their own tool’s capabilities.

Figure 2 represents how The Data Standards Cloud standardizes common data elements within your datasets, to bring consistency to the format of the metadata you create and collect.
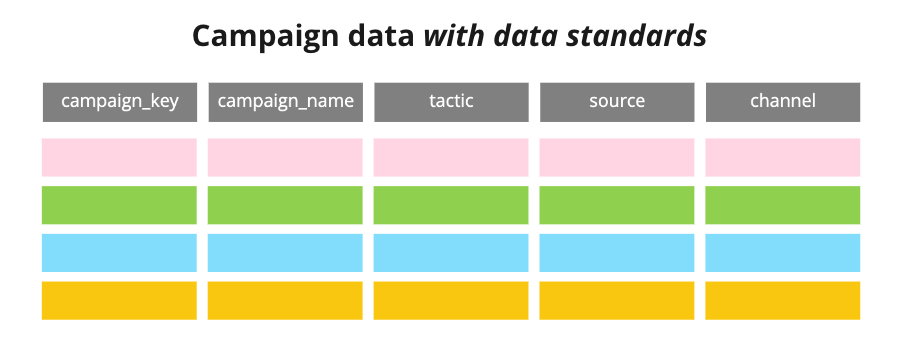
Figure 3 represents The Data Standards Cloud, Claravine’s solution to data sprawl management. A foundational Claravine core ID links disparate data together under one umbrella, combining metadata from different tools to create an enriched data asset that’s available to every team.

Figure 4 shows how this standardized, connected, and enriched data can lead to dimensionally broader analysis and richer, more accurate insights.

And this is just a fairly simple example using marketing campaign data. The same process and benefits apply to other teams’ data, too: analytics, digital merchandising, content/creative, data science, media/ad operations, and more.
The First Steps to Conquer SaaS (& Data) Sprawl
The road through SaaS and data sprawl is paved with data standards.
Sprawling teams need to build and enforce data standards in flexible templates that can be tweaked and deployed to every data-centric use case across marketing, advertising, operations, analytics, creative, and management.
Speaking and understanding the data language of all systems, and translating that to the enterprise’s standard, is essential for maintaining value and reducing SaaS inefficiencies and data waste.
The first step in this process is creating organizational change in how data is defined — or in other words, the enterprise’s data taxonomy.

Meanwhile, a data governance framework must materialize in order to identify the stakeholders, data creators, tools, and teams that will be involved in the data standards process.

And with data governance comes data democratization: the ability to unlock data control from IT-only to make it accessible to everyone in the organization, for maximum value.

Explore these resources as you pursue ROI-accelerating data integrity.
To kick off data standards within your organization, book an enterprise data strategy consultation.