


What is First Party Data? Your 1P Data Strategy Starts Here

The final days for 3rd-party cookies are were here (now Google has currently delayed to 2024).
While browsers such as Firefox and Safari led the way on deprecating 3rd-party tracking, Google Chrome (and its 50+% of the browser market share) makes Google’s announcement the official death knell for 3rd-party cookies.
It’s time to make better decisions with data for both your organization and consumers. The sustainability of your data-driven business depends on it.

Here’s what you’ll need to know to bring first-party data from the fringes to the focus of your post-cookie marketing.
Did you know? Claravine has first party data solutions for the largest brands and agencies in the world. Find out more.
Key components of a first party data strategy
Third-party cookies are essentially dead now that Google has announced its intention to phase out cross-site tracking (via 3rd party cookies) and pivot to its Topics framework. (No, you didn’t imagine FLoC, but it’s gone.)

Arguably, this change was inevitable and a long-time coming — it originated with Apple’s introduction of ITP (“Intelligent Tracking Prevention”) in mid-2017 (you can see the latest changes and enhancements regarding ITP here). However, many organizations are still considering their response to the shift in policy.
There will be a variety of ways software vendors, companies, and marketers try to address these new challenges, including “device graph,” Google’s “Privacy Sandbox”, non-cookie-based ID matching technologies, publisher alliances, and other experimental means.

Some of these are relatively untested methods with varying degrees of accuracy in effectively segmenting or targeting your desired audiences. While they are alternatives to consider, they certainly aren’t the best and only response.
Forward-thinking organizations realize we are moving to a cookieless future and that it’s time to take total control of their first-party data, making it as comprehensive and usable as possible.
Companies that have already prioritized this are poised for even more market dominance, so there’s little time to spare when it comes to addressing your 1st party data management approach.

There are several ways to do this, and we’d like to outline a handful of options. While none amount to a simple fix, the suggestions provided make the most financial and strategic sense long-term. They range from basic to intermediate, with the time to implement varied depending on factors beyond the scope of this article.
These are some of our recommended approaches.
But first, let’s refresh:
What is First Party Data?
When you submit your email address to an ecommerce website to get that coupon code, you just provided them with first party data.
When you visit the website to navigate, interact, and purchase, that (anonymized) behavior can also become that company’s first party data.
And when click a deep link within an email to hop over into (or download) the company’s mobile app, you’ve provided even more first party data.
First party data, or 1P data, is the information, and information attributes, that is handed off (with consent!) from a user to a company (or, whoever is collecting that data). The company owns this data and can use it for a myriad of valuable tactics.
The digital interactions of a user can build a data profile informed by clicks, calls, purchases, and more.
Companies can use first party data to understand and target consumers with marketing, advertising, content, and more. It provides a reliable, direct-line data track between a brand and those that interact with it.
First Party Data Standards and Integrity
Crucial to having first party data that’s actually useful is establishing data standards as you collect and create it. By structuring your first party data and its metadata in a standardized format, you create data integrity that breaks down silos between tools, teams, and partners.
Even if they’re collecting wildly different types of data, your entire tech stack (and the teams that use it) can converge via data standards to build rich, targetable, and multi-dimensional segments.
Brush up on data integrity and marketing data standards as you ramp up your first party data strategy. Likely, you’ll uncover some data to-do’s as you transition from a third party data-led strategy.
And later, we’ll explain in more detail how data standards operate throughout the enterprise workflow and unlock new opportunities with automation.
First Party Data vs. Third Party Data
To put it simply, first party data is collected and owned by the company while third party data is collected by an external source and sold to companies without the direct knowledge of the users.
What are Examples of First Party Data?
User Registration Data
Many companies, including publishers, have over-relied on third party data and avoided the process of asking for visitors and users to register to their sites. This is no longer an option if you want to develop a first-party data strategy. All the other data you gather will need to be appended to your users’ records if you still want to deliver truly personalized experiences throughout your digital marketing stack.
You’ll need to consider some creative methods for asking the user to register to the site. Here’s a prime example involving an e-commerce company.
Wayfair, for a period of time, gated their entire site with a user registration process (offering a discount upfront). Checking back in (because I did not enjoy that experience), they now give me the option to proceed to the site without registering by clicking “No, Thanks” (still offering me a discount with registration).
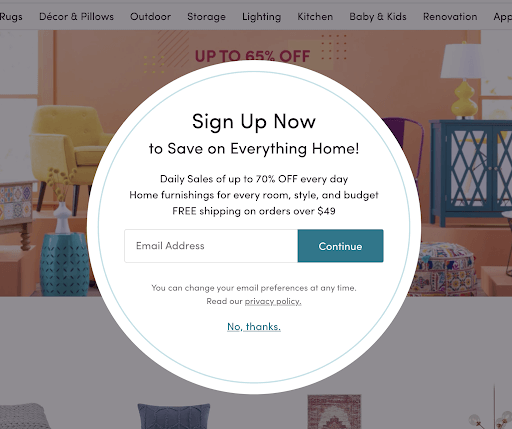
However, I’m sure this approach still generates lots of registered emails. Digging into their site for a minute, they have a “Save” button while shopping that initiates the registration process again, further positioning them to collect first-party data.
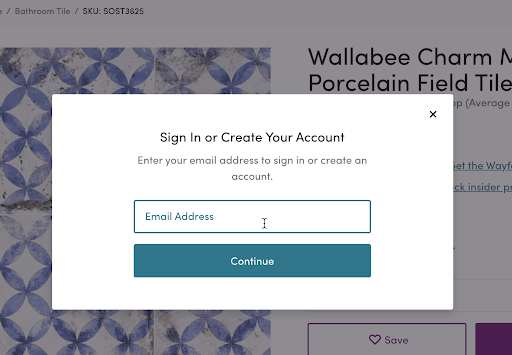
If they still don’t get me at save, once I begin my checkout process, they have a step entirely focused on collecting a singular piece of PII that will help enrich their entire first-party data process: they ask for my email (again):
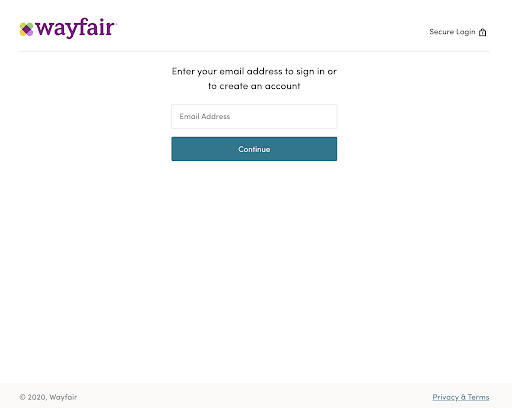
Wayfair has prioritized first-party data for a long time and continues to stay focused on it.
Outside of steps in your customer’s journey like the ones listed above, think about other places where exchanging an email makes sense for the user: newsletter sign-ups, share with a friend, etc. There are lots of places you can ask for someone’s email while they engage with your site.
Progressive Profiling
The next step beyond user registration is additional data collection about the user, specifically firmographic, demographic, and other explicit attributes you’d like to know. Asking for all of this upfront is difficult and will often kill the user registration process altogether. No one wants to tell their life story in a single form.
Instead, you should collect the bare minimum information about your users and slowly integrate additional data collection during the use of the site. Email registration alone will do the trick, to begin with, and then you can collect additional information as they engage more with your content and offers. Some tools will allow you to create an extensive form that will slowly show different form fields depending on what data you’ve already collected.
Progressive profiling doesn’t always have to be with form fills – there are a few alternative ideas here, including sending data to their profile with just button and link clicks. I’ve seen targeted emails that have a collection of buttons for the person to select from, appending with custom attributes that get automatically appended to a user’s record.
Progressive profiling via form fills seems to be more common in B2B sales situations, but if you can get away from the form and use click engagements to enrich data about your potential customers (once they’ve initially identified themselves), you can apply this just as effectively in B2C. The Microsoft Azure B2C product has some functionality that demonstrates a good option for progressive profiling by limiting the info collection on first purchase and engaging users on repeat logins with questions (e.g., birthday) that slowly fill out the customer profile.
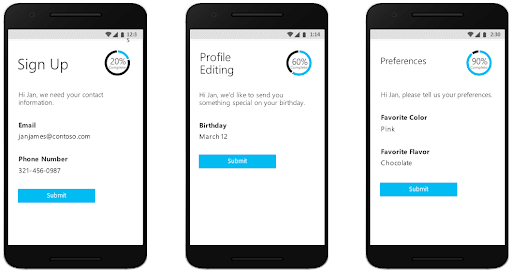
Event-Based Tracking
Beyond the basic clicks and methods described previously to append user attributes, collecting in-depth behavioral data (and associated metadata) via event-based tracking will deliver a whole different level of first-party data intelligence and profile enrichment.
Tools like Segment have changed the game when it comes to not just implementing event tracking but mapping and passing that data to a slew of “Destinations,” including CRM, Analytics, Ad Tech Platforms, Raw Data storage, and more.
By using “track” and “identify” calls (tech speak from Segment), you can save event properties and user traits and proliferate that data almost everywhere.
For example, the identify call, which “specifies a customer identity that you can reference across the customer’s whole lifetime.”2 You can append traits, both standard and custom ones, to the user identity and that, my friends, gives you an edge on delivering a good experience.
Similarly, the track call records events performed by the user along with associated properties e.g., values input into a search or filter on your site. Combining identify and track calls enriches your first-party data.
I’ve been part of some excellent implementations of the above, watching this type of data port over to behavioral analytics platforms, CRMs/Marketing Automation solutions, custom databases, ad delivery platforms, and more. I’m surprised that it’s not commonplace.
Note: this is a basic breakdown of what can be a very in-depth and challenging set-up. I highly recommend it, but it’s something you want to approach with great attention to detail.
Make Sure Your 1P Data Strategy Pays Off

If you’re going to do this, do it the right way. Here’s how.
Data Creation Automation and Standardization
There are many areas of the business where you have no choice but to require human-created data e.g., content development, digital/media campaigns, promotion codes or product catalogs. All of these data/content objects require extensive metadata that is often input by internal or external team members.
And, while there is a finite amount of major data/content objects an organization needs to manage, the number of underlying records, data points, and hands creating them is significantly higher. Think: for every one digital campaign, there may be 1000+ unique tracking links required across all channels.
With coordination, standardization, and governance across all teams filling in your metadata (a fancy way of saying data attributes) for these objects, your first-party data will benefit considerably. You may have 32 different unique attributes that you want attached to a campaign link or piece of content. If you are creating this data properly, automating, and enforcing standards, it will flow into and enrich your owned data (aka first-party data).
Conversely, if you are not coordinated across teams and users, your first-party data is at risk for inaccuracy and an inability to be used meaningfully. It’s probably the number one reason your data quality is poor and should be a top priority for any data-driven (and first-party-data-driven) organization.
Tools like Claravine have been built to address these very challenges and have been adopted by some of the biggest organizations in the world because they had the foresight to be a “first-party-data-first” (…I apologize for that) company.
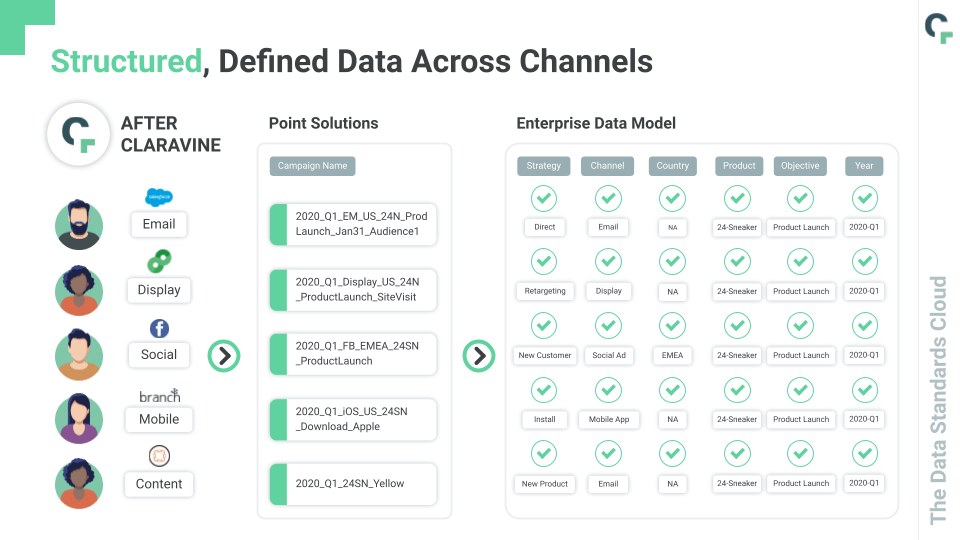
That’s how you take org-wide data like this:

And turn it into enriched, multi-dimensional data like this:
Aside from the above-mentioned approaches, there are some other notable considerations listed below:
First Party Identity Graphing/Resolution
Aligning your data strategy for building out your customer profiles is important, but it also requires the technology and tools to put this data to use within your organization. Platforms like LiveRamp with IdentityLink can help augment your identity and connect it into the digital ecosystem. Historically this has been very difficult, but IdentityLink reduces the barrier to entry for both identity resolution and incorporating identity into any attribution and measurement solutions.
A few other companies that can help connect your first-party data into the digital ecosystem are LiveIntent, Conversant, and Oracle OnRamp. In some cases, the best path can be to go directly to the likes of Google and Facebook for engaging current customers or acquiring new customers.
Customer Data Platforms
Oh, the “beloved” customer data platform (CDP in short) – how crystal clear you are as a solution and market…I jest. There may be a CDP solution that is perfect for your organization; however, it is way beyond the scope of this article to make recommendations for CDPs other than it is worth taking a look. I know that David Rabb runs the CDP Institute and has built a tremendous resource for research into these types of solutions. I’d be doing you a disservice to say anything other than use that site if you’re considering a CDP.
Second-Party Data Partnerships and Enrichment
Second-party data is a more labor-intensive effort and isn’t technically first-party data. It becomes first-party data when you secure the information into your data systems.
Aside from developing direct relationships with other companies to purchase data, Private Data Exchanges from companies like Lotame, Narrative.io, and other data provider marketplaces are becoming increasingly popular (part in due to new privacy regulations and changes we’ve mentioned in this article).
There are some useful benefits to these exchanges/marketplaces and direct joint data partnerships as well. For example, it can match data imports to your datasets against users and device IDs for enrichment. It also gives you the ability to continue more targeted advertising efforts without dependency on 3rd-party data. You can be more specific with the publishers you want data from.
Note that not all of these data exchanges may be tied directly as a 1:1 relationship to your users, but they still have value to your digital advertising efforts.
Alternatives to First Party Cookies
Even first-party cookies, while having some value, can be deprecated for better client-side data storage practices.
One, in particular, IndexedDB, has a lot of merit for implementation. This is a tangential improved data practice that doesn’t store first party data in (for example) a data warehouse associated with your full user/customer dataset. Despite this, the practice still has value in creating a data flow and experience to your user’s browser for better user experience. One application of the API is “to store user-generated content, either as a temporary store before it is uploaded to the server or as a client-side cache of remote data – or, of course, both.”3
With some programming wizardry, you could append this data to a master record for the user, save it in unstructured data set and run a semantic or sentiment analysis tool against it to understand more about your customers/users. Though, I think what’s been described here can also be done with the event tracking process outlined above.
Note: I am not a true developer. Check with your favorite developer to see if I’m crazy or if that’s possible and a good example use case…they’ll probably say “maybe…but” and come up with a much better solution 😉
Next Steps: 22 (More) Ways to Collect First Party Data
I know that we face new challenges to maintain effective advertising strategies without the use of the 3rd-party data we once relied upon.
However, as outlined above, there are a variety of solutions to get started on right away and, most certainly, more creative solutions being developed for better customer experiences that also support a more thoughtful approach to the cookieless future and customers’ deserved data privacy.
Learn more about what Claravine is doing to help usher in this newer and brighter digital future.
Understand exactly why advertisers are flocking to first party data with this study and infographic breaking down the rapid sector growth. Plus, an in-depth look at 3P cookie alternatives.
And in the meantime, expand your first party data strategy with these 22 Ways to Collect First Party Data.

Interested in learning how Claravine helps automate, standardize, and optimize your first-party data? Get started here.
About the Author
 Michael Shearer has been fortunate to work in the digital field for more than 20 years – with an expansive career in digital marketing, analytics, operations and more. He is currently the Head of Digital Marketing at Claravine. He has written articles for a number of online publications including MarketingLand, Search Engine Land, Spin Sucks, Relevance and more. He holds advanced degrees in Information Systems and Management from Drake University and American Public University. Michael resides in Colorful Colorado with his wife and 5 children.
Michael Shearer has been fortunate to work in the digital field for more than 20 years – with an expansive career in digital marketing, analytics, operations and more. He is currently the Head of Digital Marketing at Claravine. He has written articles for a number of online publications including MarketingLand, Search Engine Land, Spin Sucks, Relevance and more. He holds advanced degrees in Information Systems and Management from Drake University and American Public University. Michael resides in Colorful Colorado with his wife and 5 children.