

How to Prepare Your Data for Adobe Experience Platform

As a newly announced Adobe Premier partner, we’d like to share some key ways you can prepare your data to thrive in Adobe Experience Platform, specifically, how to prepare content and campaign data within a common data model.
Note: Not a prospective Adobe Experience Platform user? Read on. Cleaning up your data will help with any organization’s effort towards better experiences and personalization.
Adobe Experience Platform 101
Adobe Experience Platform is Adobe’s version of a Customer Data Platform, providing a unified customer database that is accessible within other Adobe services. Adobe Experience Platform combines and unite all kinds of data sources. Once it’s prepared, you can activate it across channels, creating a single source of truth and a system of record for both data and content.
The current challenge
It’s difficult to make data match with content and present the most relevant experience for a customer. To elaborate, many organizations right now are finding it difficult to do personalized marketing at the granularity you need using just first-party data from enrichment through your own digital properties.
It’s almost impossible to keep all data standardized to confidently answer questions about who the customer is, their demographics, or your company’s past experience with them. Trying to then store, retrieve, and intelligently select and deliver the relevant content they need to see to have a valuable experience is not always possible.
The problems Adobe Experience Platform solves
Adobe’s solution provides an option for organizations to create real-time CX profiles, and in Adobe VP of Information & Data Services, Mark Picone’s words, “a place for all data to flow into in one central seamless fashion. And what it really provides is to connect the dots and eliminate the manual stitching that would normally have to be done across many areas of the organization.”1
Adobe’s Experience Platform seems to be a solution to many problems. Indeed, the VP of Adobe Experience Platform Engineering, Anjul Bhambhri, highlights that the platform can help large enterprises start to structure the way they approach data.
Some of the complexity
With a significant financial investment and hardcore data architects required to sift through the organizational data sets and records needed to build these robust profiles, you need to make sure that those systems are ready to be ingested.

The nature of licensing and implementing Adobe Experience Platform also suggests that we can’t treat Adobe Experience Platform like the figures illustrated by marketoonist.com. The cartoon describes a larger issue we see in most organizations we work with: it’s very common for teams to throw new tech at their data problems. With the rapid proliferation of new marketing systems (each with its own data language and workflow) in the last decade, manual data quality processes can’t keep up with the amount of data being produced; data issues increase exponentially as the stack grows.
This applies to large enterprises wanting Adobe Experience Platform, too.
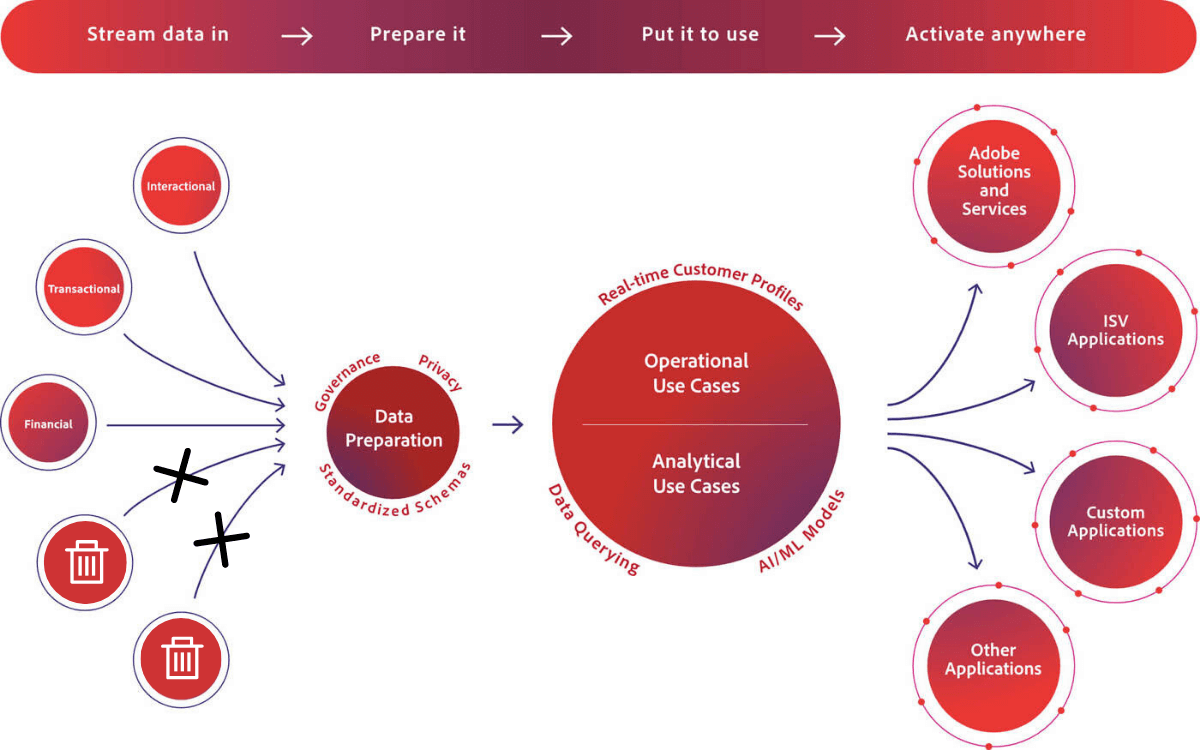
We won’t get too technical, but there’s a lot of ETL, effort, and heavy lifting that goes on in Adobe Experience Platform to make sure the data is ingestible. For example, something as simple as making sure you don’t log into a system and throw everything off downstream by changing a tracking parameter or moving a comma to a period in Salesforce or some other system. There’s a cost associated with that work.
Additionally, pushing content and experiences (that you couldn’t before track the effectiveness of) to each of those records, personas, and segments you’re building in Adobe Experience Platform, will further obscure and complicate the views you’re trying to produce. This aligns very well with the familiar idiom ‘garbage in, garbage out’ as it applies to data.
At the end of the day, ETL can only do so much.
You’ll have to examine your holistic data practice, since a complete and accurate customer data profile is what you’re trying to get out of Adobe Experience Platform.
Back to the start: metadata
Recognizing the potential of Adobe Experience Platform depends on the quality of data set(s) an organization intends to ingest. We return to our original point: Given the cost and resources required to implement and optimize Experience Platform, data cleanliness will be a major factor considered when assessing the potential that Adobe Experience Platform will work for your organization.
Doing the work now will make Adobe Experience Platform worth it, especially when new relevant experiences leads to greater customer satisfaction and retention.
How should you start? With the root of a lot of data issues: Metadata.
There may easily be 300+ unique data points used to track cross-device experiences to track correctly to make sure a user gets the right customer experience. Lot’s of metadata goes into organizing those data points, and they’re often overlooked by teams and organizations.
When we look at all the data points that go into building a good experience, here are a few examples of metadata:
- Product Catalog: SKU, Name, Category
- Campaign Specific Information: Name, Placement, Ad Group, Objective
- Creative: ID, Type, Name, Dimensions, Tags, Placement
- Experience: Web Page, Text, Image, Video, Mobile App
- People (Provenance): Team, Channel, Group, Business Unit, Agency, Region
Metadata comes together to tell the story of your content and campaigns. Improving how your company creates and maintains experience metadata will be key to creating good, contextual data in your marketing and content systems. By extension, it will also introduce the required context and quality needed in data sets ingested into Adobe Experience Platform.
The process we suggest to do this is by governing your content and marketing data in a common data model.
Preparing a common data model
The goal of a common data model is, in line with Adobe DX stack’s fundamental premise, that
data matches with content, presenting the most relevant experience for a customer.
Where ETL and governance within Adobe Experience Platform knits together existing data, a common da
ta model addresses data fragmentation across the enterprise at data creation. Standardization at this level maintains data standards across internal and external content and campaign creators.

There are three steps to creating and governing a common model:
- Align teams on common enterprise taxonomy
- Implement automated and governed process
- Manage and connect data centrally (create a single source of truth)
Align teams on a common enterprise taxonomy
The first, essential step in governing a common data model is, in many cases, also the most time consuming and challenging. Some common elements or benchmarks:
- Gather spreadsheets across different teams who manage content and marketing data in your organization
- Understand what external teams, such as agencies, are creating campaigns and metadata
- List what point solutions, including duplicates, your enterprise uses
- Collaborate and agree upon universal taxonomy elements (for example, Name)
- Collaborate and agree upon unique taxonomy elements
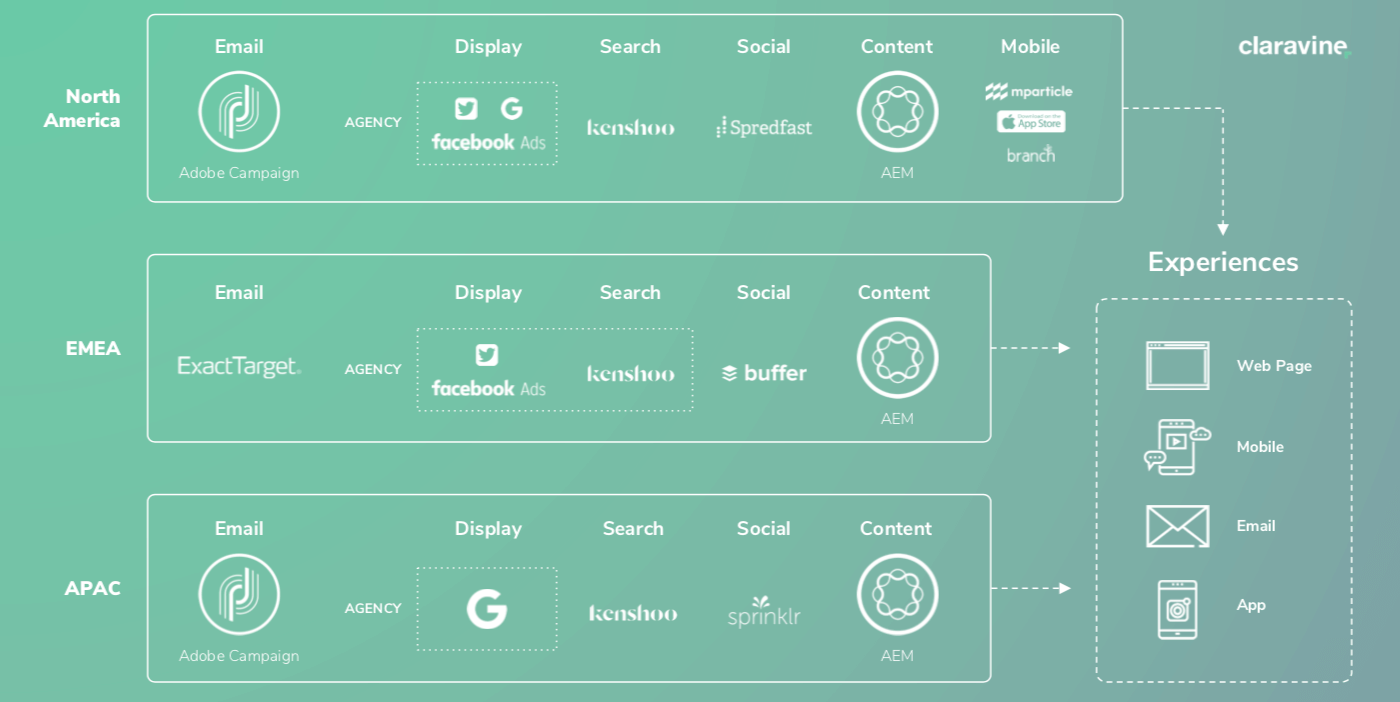
One quick example to illustrate what this might look like for a large enterprise, to highlight the necessity of a common taxonomy across all teams and systems.
There are two levels: solutions (which may be standardized in silo), and people (many people in different versions of different solutions).
In this example there are 3 agencies running 5 different point solutions for 4 channel teams in 3 geographies, trying to create 4 experience types representing a unified brand. This doesn’t take into account all of the other internal teams and solutions, representing potentially thousands of individual employees, managers, and marketing and content contributors.
It becomes very difficult, very quickly, to have any sort of standard naming convention or standard set of metadata to drive experiences across the different channels.
Consider a single field pretty common across all solutions: Campaign Name. There’s logic that goes into creating a campaign or creative field. From an ETL perspective, pulling all that naming data into the same place without the context from all the teams who created a unique logic behind the field, it’s hard to understand what the component means anymore.
You can get more detail on this process by viewing our Analytics Nexus webinar, where Melinda Geist talks about how they established this taxonomy at Intel.
Implement an automated and governed process
Once you have a taxonomy established across the enterprise, you’ll have to implement a process to maintain the taxonomy at-scale. Having a taxonomy doesn’t necessarily mean people will use it correctly 100% of the time.
Usually this looks like a tool that alerts each of those teams of the taxonomy that is in place, sets ‘guardrails’ to help them follow that standard governance process, but still allows them to work and execute independently. This kind of process will help you avoid scenarios in which fragments of information or metadata are deviated from and forgotten or omitted.
Using the previous ‘Campaign Name’ example this process should essentially help you avoid this:
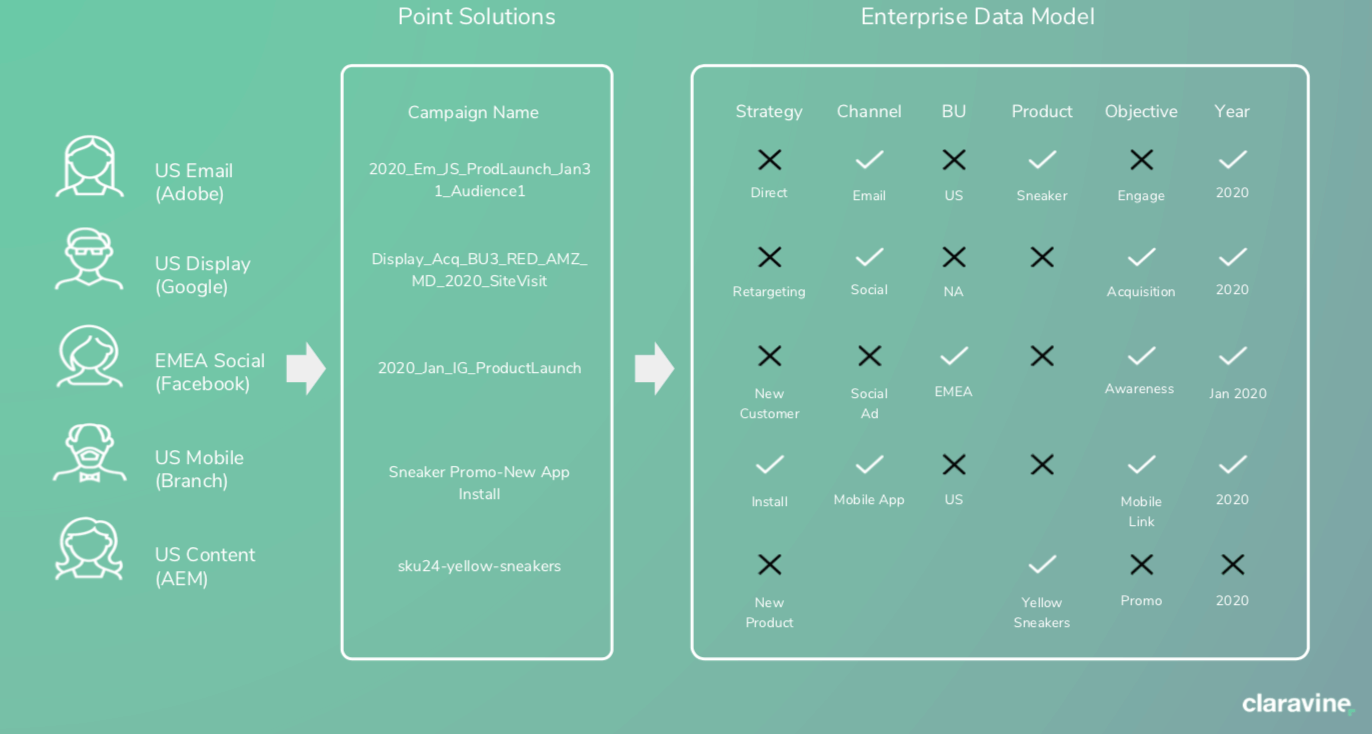
And ensure this:
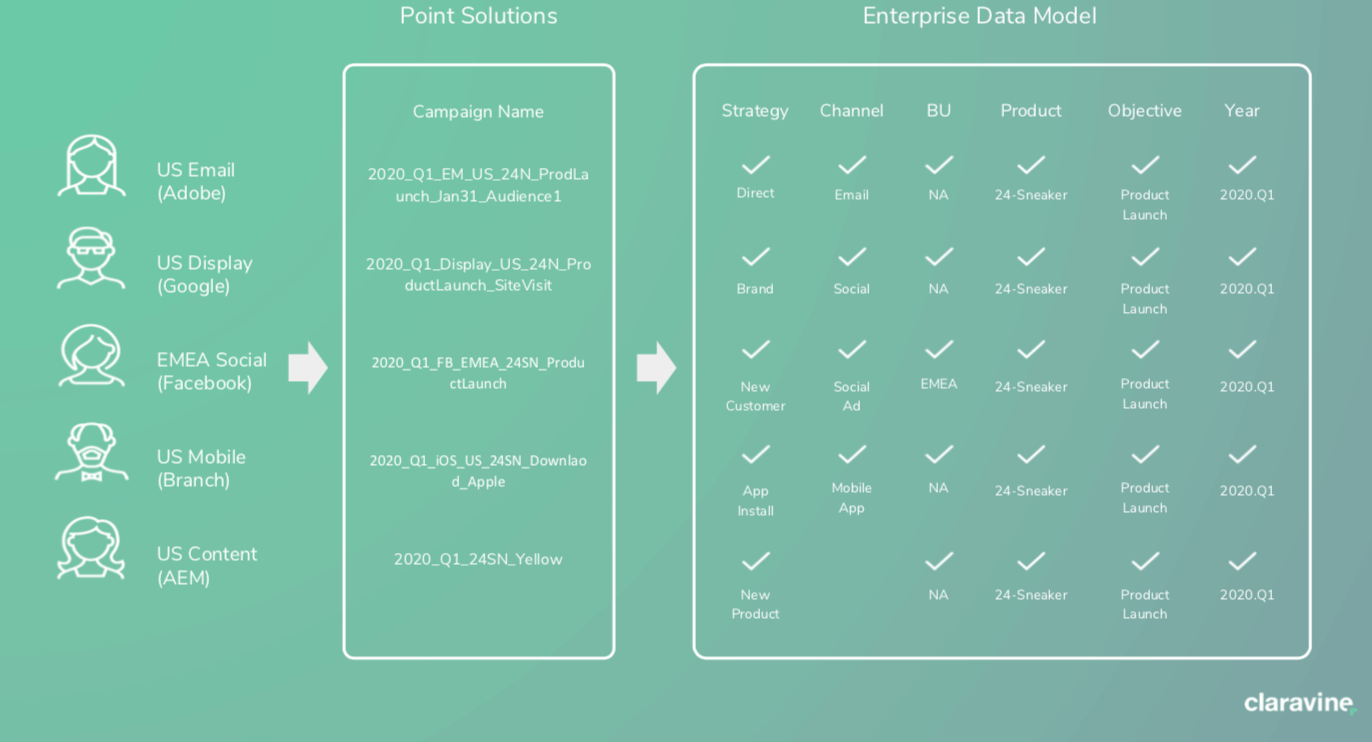
Using a governance solution across all those different points, solutions and teams will act like a taxonomy ‘filter’ for all the different systems that are delivering experiences and providing the analytics to the business.
And while adhering to standardized naming conventions is important, even more critical is making sure that the link creation and corresponding tracking codes are accurately created and used with 100% consistency. Again, while ETL has it’s utility, if you have broken tracking to start, you can’t go back and ask consumers to click on your ads or emails again. If the data is not there in the first place at the time of engagement, it won’t port properly to the corresponding customer record and there’s no option for ETL either.
To help here, we have a primer on tracking code management as well as some recommendations for tracking code structures.
Manage and connect data centrally
The third element to governing a common data model is to manage and connect your data centrally. At this point of the process, you have standards for how things will be named, and all of the data you can see follows the same criteria.
While that alignment on that common taxonomy is a great start, it can’t stay static in an enterprise setting: standards will change over time and new fields will be required. You want the management of the taxonomy and the data to be centralized so changes can be easily pushed to different teams.
Note that a lot of times, taxonomies are stored in spreadsheets. Aligning a taxonomy under a central data model will probably push you away from that method.
We’ve included a couple of examples of how this might look for content and campaign data.
Content Data
If you’re an Adobe customer, you’re likely using AEM as an activation layer and a CMS on the publishing side, whether it’s the Ad Cloud Campaign for email, Experience Manager for the web or Adobe Target for personalization. Regardless, everyone using these systems has metadata tied to their digital assets.
Centralized taxonomy for content metadata and naming conventions includes:
- A governed content tagging process
- Ability to manage and change metadata across teams
Centrally managed, complete content metadata has several advantages. When looking at preparing your content data for Adobe Experience Platform, this final step will help by:
- Having a single process for different digital asset management systems (DAMs). All content contributors will tag all content with the granularity needed to recall assets in campaigns or personalized experiences later.
- Evolving standards are manageable. A central system to modify content metadata will help to control what data can be changed and what’s locked down. It also acts as a record for evolving tags or last minute changes.
- You’ll spend a lot of time flattening this data layer in Experience Platform. Centrally managed, robust content data ensures that you don’t waste your time going back to clean up the multiple terabytes of digital assets you activate.
- Universal tagging and other content metadata controls will make asset recall much easier. You’ll know that the asset or the experience someone sees fits with the specific, curated micro-segment pulled from the data layer in Adobe Experience Platform
Untangling the mess of missing metadata and disjointed taxonomies will be worth it in the long run. While the chaos may ‘work’ on a small scale, you’ll appreciate the organization once your business invests in this data platform and you have all these robust interesting segments and perfectly managed assets to show them.
Campaign Data
Simila
rly to content metadata, managing campaign data in a common data model looks like:
- A centralized taxonomy for campaign data and naming conventions
- A governed process to generate and implement campaign tracking across systems
- Automatic validation and monitored pages, tags and data readiness
- A process to centrally manage data formats and flows across the ecosystem and teams (your email team has a very different set of needs than your paid media team or someone running Facebook ads. And so you have to have a data model that can conform and fit their needs while also being able to manage and pass it into other analytics, BI, and other teams)
A Case for Claravine
To illustrate the effectiveness of a common data model, here’s a quick example from one of our customers who used us to improve their media:
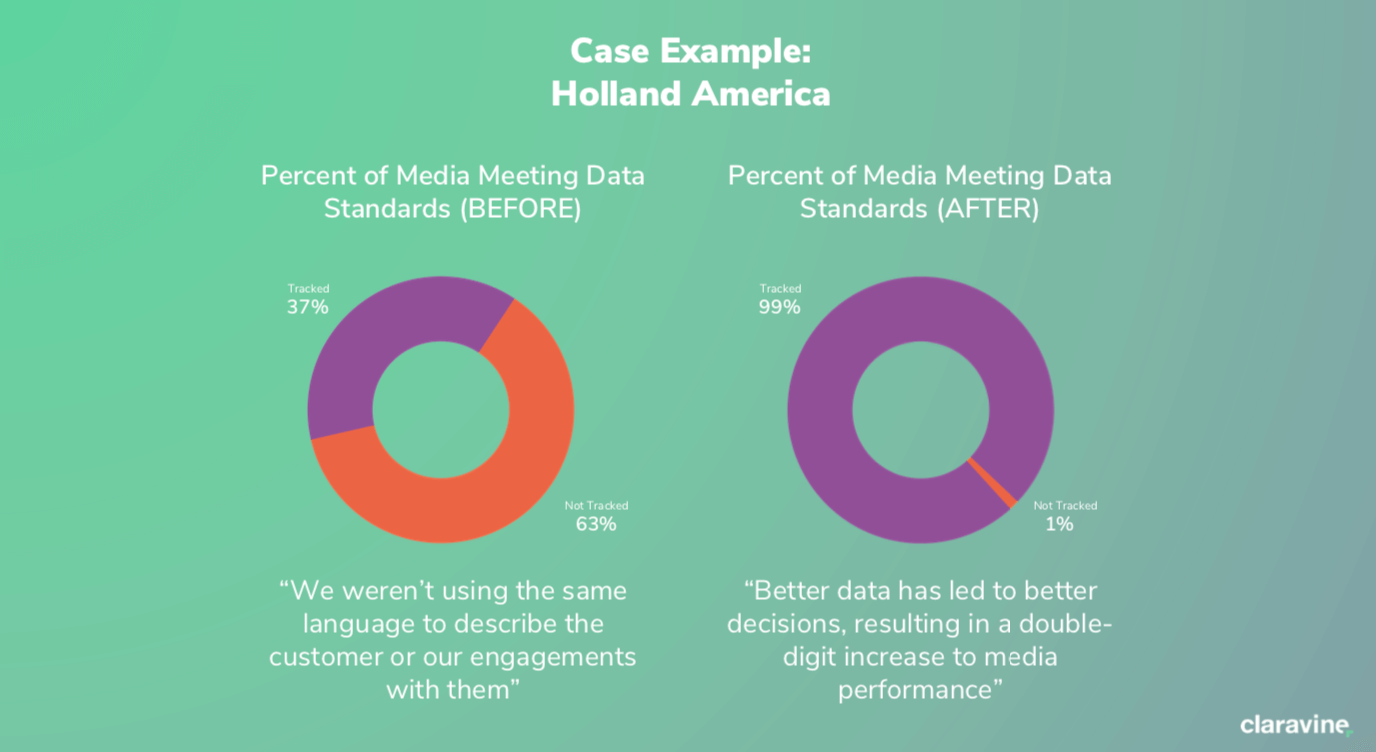
This subset of data is one among many that prospective Adobe Experience Platform users will have to clean up before they can qualify or start to implement Adobe’s newest platform. Once in place, Claravine acts like a data filter, allowing you to prep historical data and lock data standards in place. You can have the confidence to know that data is going to be effective once compressed down in Adobe Experience Platform.
In the case that your content or campaign data needs a little help, here are a few ways we can help:
- Journey Orchestration. Where the journey build capability in Experience Platform is a powerful one, Claravine fills a ‘visibility’ gap. When you clean up and govern your taxonomy, you give yourself the power to know, in context, what you’re serving as your experience. In the case of Adobe Experience Platform, Claravine gives you the ability to know what’s being fed to the platform, and how effective it was from the beginning.
- Accelerated Timeline. Claravine plays a part in the bigger data picture, but you can make each data segment available as it comes online. For example, with a CRM system, you’re looking at sets like account type, industry, level of spend, or footprint. With Claravine, you can significantly decrease time-to-activation for enterprise content and campaign data and time to prove a return on investment.
- Prove Value Quickly. Holding off on addressing metadata and taxonomy will add months to your activation plan. Using a data governance model will help your CMO or CIO avoid a huge CapEx hit, and prove that the solution is moving the needle for your org.
If you’re ready to learn more about how Claravine helps, get started here.
About the Author
 Michael Shearer has been fortunate to work in the digital field for more than 20 years – with an expansive career in digital marketing, analytics, operations and more. He is currently the Head of Digital Marketing at Claravine. He has written articles for a number of online publications including MarketingLand, Search Engine Land, Spin Sucks, Relevance and more. He holds advanced degrees in Info Systems and Management from Drake University and American Public University.
Michael Shearer has been fortunate to work in the digital field for more than 20 years – with an expansive career in digital marketing, analytics, operations and more. He is currently the Head of Digital Marketing at Claravine. He has written articles for a number of online publications including MarketingLand, Search Engine Land, Spin Sucks, Relevance and more. He holds advanced degrees in Info Systems and Management from Drake University and American Public University.