


Tracking Code Structures: Pros & Cons
Many teams we work with run into a common situation: they want to include certain elements like source and product name in all their campaign URLs so they can easily export that data, run personalization, or other actions based on those values. They realize in hindsight that not all of their classifications are enabled to collect that metadata, and miss out on some valuable insights; so the taxonomy realignment process begins. Essential to that process is choosing your tracking code structure.
If your team or organization is going through something similar, we want to help you avoid some duplicative work and empower you to make informed decisions that help the roll-out of your new taxonomy go a little smoother and faster.
Here are a couple of options to consider with your team before you decide on your final tracking code patterns, with some pros and cons for each:
Long Tracking Codes
Tracking Codes by Tool Type
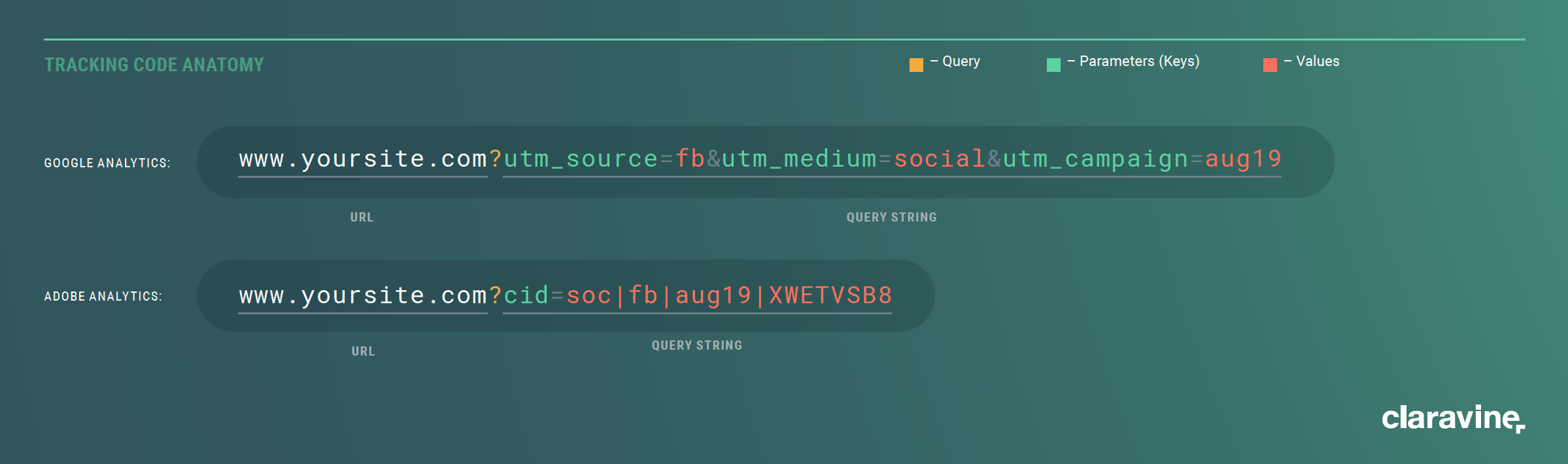
Marketing campaign tracking codes, which collect data about a user’s click to a webpage, are most often populated via a query string parameter appended to a URL. The name of the parameter is considered the key, and the contents are considered the value. Each analytics platform is configured to look for specific query parameters and send the values of those parameters to the relevant reports. For example, Google Analytics parameters include: utm_campaign, utm_medium, utm_source, utm_content, utm_term. Conversely, Adobe Analytics only requires one parameter which is defined by your organization (typically a cid or cmp). Adobe Analytics then leverages “classifications” to associate custom metadata to that parameter in your Adobe Analytics reporting. It’s important to note that Google Analytics can also add additional custom metadata to your reporting. To do so, you would implement the Data Import feature to leverage one dimensional key across other dimensions – be it the default dimensions or “custom dimensions.” Tracking codes facilitate the analysis of campaign performance and allow a view of performance metrics aggregated by different metadata about the campaign.
Rule Builder
What is the rule builder? Who configures it?
Adobe’s Classification Rule Builder allows you to create rules for how Adobe reads or processes tracking codes. It is a solution within Adobe that is sometimes used to eliminate the need to import / export classification data manually or via FTP. Typically, the person responsible for configuring these rules is someone on the analytics team — an analytics manager, analyst, or whoever is working closely with the Adobe reporting and spearheading the overall taxonomy.
If you are using Classification Rule Builder, you will most likely leverage regular expression (regex) formats. You’ll have a long tracking code that’s typically a concatenation of abbreviated values with a delimiter, such as an underscore or dash between each. For example, you could create a rule in Classification Rule Builder using regex to say that the first parameter or the first five characters should map to your Marketing Tactic classification, and the next five should map to Marketing Source.
Essentially, the tool is a way to parse out tracking code values within Adobe.
*A note on classifications rule builder + Claravine
If you are using a tracking code taxonomy that is a concatenation or abbreviation of all the values you want to capture in Adobe and you want to edit the classification data associated with a specific tracking code:
- If you are relying solely on Rule Builder to parse your tracking codes to populate classification data, then manually correcting classification data will not solve your problem. Since you are modifying the classification data and not the tracking code itself, when Adobe re-reads that tracking code, the rule-builder rules will re-run and apply the same logic.
- If you’re not using Rule Builder and you are using Claravine to send that data via classifications, some people internally may be confused. For example, say you need to switch up the social media channel from Twitter to Facebook for a tracking code that was pushed live. The tracking code is going to say TW for Twitter, but the classification will say Facebook because that’s what Claravine will update it to. Essentially, the tracking code doesn’t match what’s actually in an Adobe from a classification perspective. *Note: this is not a system error; consider obfuscating to avoid confusion
Processing Rules
What are processing rules?
Marketing Channel Processing rules are used to define if a visitor hit meets the logic assigned to Adobe’s marketing channels (unlike Rule Builder, which looks solely at your tracking code and is building classifications associated with an eVar). Processing rules are applied in a cascading logic and tell Adobe that when data comes in, it should follow each set of commands based on user-defined conditions. It is important to note that data collected with these rules are permanent and cannot be changed retroactively.
A couple of examples:
- Anything that comes in with ‘dis’ tracking codes put in the Display bucket.
- Anything that comes in with a “gclid” query parameter put in Paid Search channel
- Social Referral channel. You can set up rules to push traffic that comes from social network sites
- Adobe has Paid Search and Organic Search detection which you can also set up and use in your Marketing Channel Processing Rule logic
One thing to note is that rules are most commonly based on those first two or three characters within a tracking code. You have the option to be more specific, but usually, it will involve only the first few characters if you are using the tracking code as your logic.
Again, the important thing to remember about processing rules is that they define your marketing channel bucket, not your tracking code classifications.
***Be sure to check if your team has set up processing rules and/or rule builder rules before making any changes to your current taxonomy structure because it could have downstream effects:
- If you currently have processing rules and/or rules within rule builder and switch to completely obfuscated tracking codes, the current rules in place will likely break, and you will not see any data in Marketing Channels or your classifications.
- If you currently have processing rules and/or rules within rule builder and switch the structure of your taxonomy (still using a concatenation methodology), the current rules in place will break, and you will not see any data in Marketing Channels or your classifications.
Benefits & Drawbacks
What are some reasons why people prefer or avoid long tracking codes?
Here are some reasons we (and a lot of the brands we work with) avoid them:
- You’re more susceptible to URL errors. Some analytics reporting, whether it be Adobe or Google, they’ll cut off the URL after a certain number of characters. Sometimes marketers, when we’re applying these tracking codes, we’re just thinking this is the only tracking code that’s going on that URL, but that’s not always the case. If you get into something like DoubleClick or any other DSPs or ad servers, they may also append additional tracking code values. Therefore, you run the risk of them being cut off if they’re put at the end – losing information or tracking altogether.
- Long tracking codes are readable (by audiences and competitors). It’s relatively easy to scan a long tracking code and determine what the content is. Given all the types of audience targeting and personalization that you can do with ad targeting, usually, you don’t want your audience seeing what type of targeting they were defined with. Additionally, from a competitive perspective, you don’t want your competitors to know what your marketing tactics are.
Here are some reasons why people choose to use them:
- Data quality problems. Some people prefer long tracking codes because they are human-readable. If this is you, it might be an indicator of a data quality problem. Inconsistencies may make using Adobe to query classifications and get data you want difficult. Long tracking codes allow someone to filter the tracking code in Adobe; it’s a ‘band-aid’ workaround, but still works in some cases.
- Targeting. Some people like to include the audience type or product name in a long tracking code to query those parameters out of the URL and use them for targeting purposes like personalization.
- Reliance on rule builder. If you’re using rule builder, no uploads are required. Some people just want to avoid FTP or API.
Obfuscated Tracking Codes
The traditional taxonomy structure is essentially a concatenation of multiple values where you see channel, audience, marketing tactic, campaign dates, and campaign name all visible in the user-facing URL. In contrast, link obfuscation employs different methods to obscure those values in the query string, usually by appending a unique string of values. Please note that link obfuscation is not the same as link shortening.
We get lots of questions about link obfuscating as audiences become increasingly niche. Also, because it’s extremely difficult to manage and ensure value strings are unique when working in an excel macro or google sheet. Obfuscating tracking codes does not limit visibility in the metadata available, and it will not delete data.
Adobe Setup
Is obfuscation just an Adobe function?
With Adobe, you can obfuscate tracking codes because of the functionality to classify tracking codes in the analytics platform. Users define the key, which is the tracking code, and then define the associated metadata. Historically, Adobe users may be more familiar with the concept than Google users.
In Claravine, obfuscation is automated; it generates either a random number or random text string (or both), which is the tracking code, and sends the associated metadata into Adobe.
ETL
If you’re not working in Adobe or Claravine, some companies may choose to develop internal tools that generate tracking codes. In some cases, these codes will be obfuscated. At this point, the tracking code won’t have any metadata attached. In these cases, metadata will still have to be imported into Adobe separately.
Obfuscation Outside of Adobe
I’m not an Adobe Analytics user, can I still obfuscate my tracking codes?
You can manually create tracking links individually in Google Campaign URL Builder and some other web utilities, and by incorporating utm_id, you don’t need your utm_campaign to tell the whole story of your user.
Google / Custom Dimensions
If you have a Product ID, the metadata associated with that would be the SKU number, the color, the name, etc. In Adobe, those associated values are called Classifications. Essentially, you classify the information associated based on a key. With Google Analytics, the closest concept to this is custom dimensions.
‘Out of the box,’ Google has five different tracking codes called UTM parameters. Some organizations like to include custom dimensions to import more metadata and granularity to their analytics reporting.
So how is this related to link obfuscation? You can achieve link obfuscation in Google by creating custom dimensions and a utm_id (that random string, which is your tracking code). It will push the associated metadata into custom dimensions within Google.
You can try it out by going into Google Analytics under Admin > Data Import > Create. Select Campaign Data: 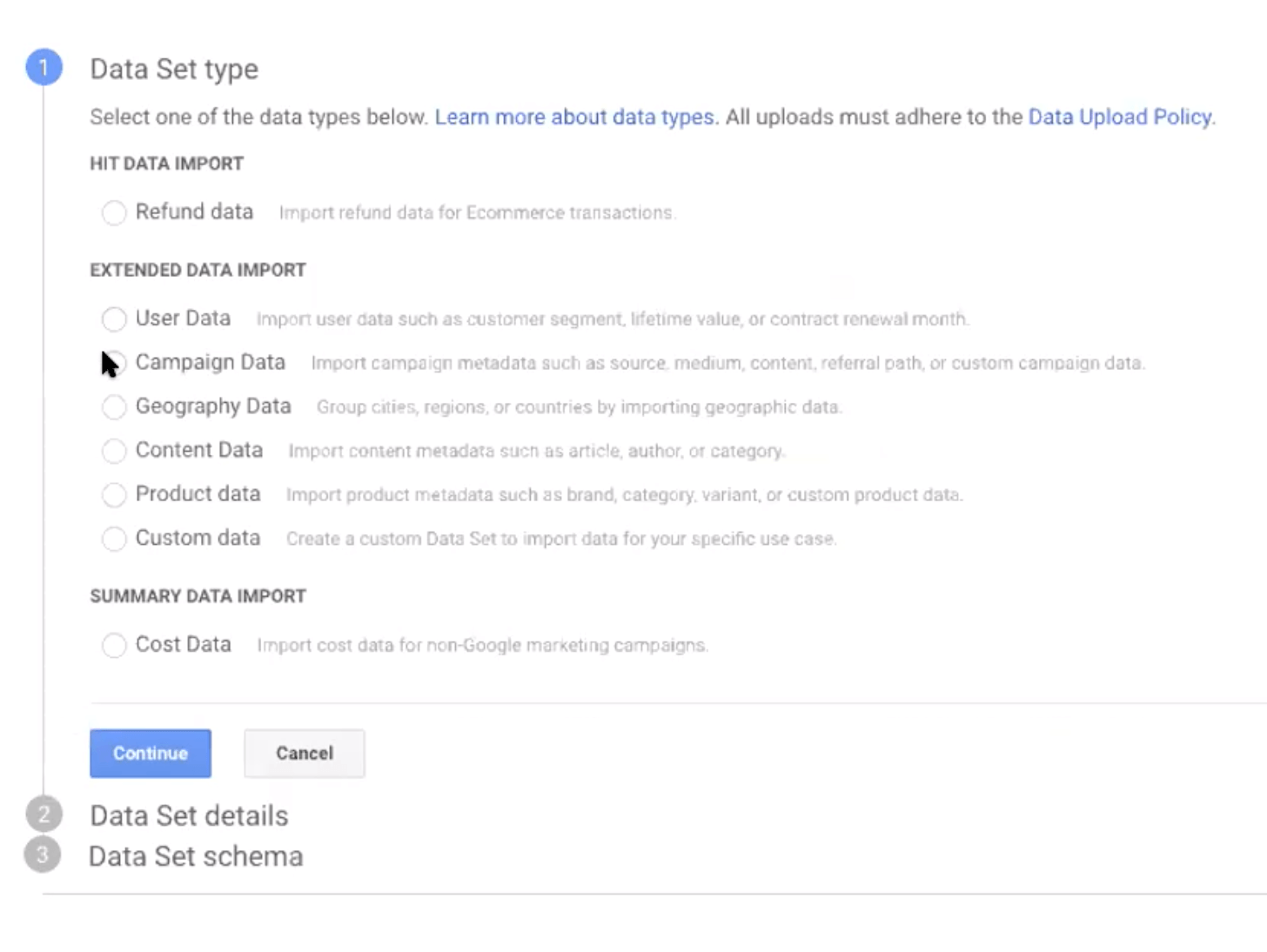 We’ll input ‘Test’ and select a view.
We’ll input ‘Test’ and select a view. 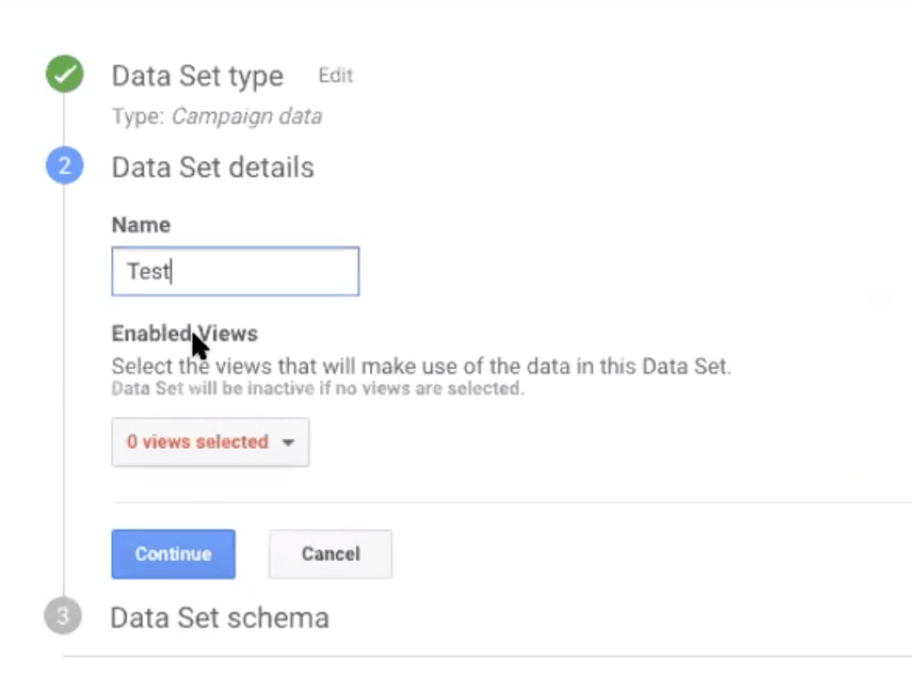 Select the data you want to include.
Select the data you want to include.
Some teams like this method because you’re not limited to the traditional five UTMs that are standard to Google Analytics, which pass to source, medium, campaign, term, and content. You are allowed to collect more data than Google would traditionally allow you to have in your reporting .
One thing to note here is that if you do use this method of dimension widening for Google Analytics, in certain instances, you’ll have to build a custom dashboard to view the custom dimensions.
Benefits
Why would I choose to obfuscate my tracking codes?
These are the most common reasons why people like to obfuscate their codes:
- It helps to shorten the URL
- Prevents users from omitting the tracking (e.g. on social, paid search)
- Obfuscation keeps your marketing tactic data or other proprietary knowledge and targeting data internal
- Competitors won’t be able to see what metadata is associated with that tracking code
Downside
Why wouldn’t I obfuscate my tracking codes?
These are the most common reasons why people might not opt to obfuscate:
- Personalized ad content. Some organizations use parameters from a long URL as a prompt to provide a specific creative. In these cases, teams may prefer to keep long trackings codes to continue personalizing content in this way.*
- If your governance system requires the internal user to manage all of your tracking codes by just looking at them, they’re a lot harder to manage when you get naming inconsistencies
*A note to Claravine users: you can obfuscate your tracking codes and still personalize ad content.
Features to Highlight
While we’ve included the major elements to consider when choosing your tracking code type and structure, we also want to highlight how Claravine weaves itself into tracking code creation. For our customers and other readers, these features interact with (and improve on) some of the common ways practitioners deal with tracking codes day-to-day.
Pattern Builder
What is the benefit of the pattern builder?
The main benefit of the pattern builder is that it ensures standardization and consistency across channels when creating your tracking codes.
Avoiding duplicate values
How does auto number and randomize guarantee unique values?
Ensuring uniqueness in a spreadsheet is difficult, which is unfortunate since duplicates can skew results and cause reports to be inaccurate. Claravine centralizes the creation of all tracking codes and guarantees that random strings and values are unique within each pattern you create. Auto numbers and random strings are tracked in each pattern and will not duplicate for the included templates.
Placeholders are created for the unique value and the auto-incrementing number until you click Submit. Upon submission, Claravine keeps tracking of used auto numbers and random strings and will not duplicate.
Several of our experts have had customers that use an auto-incrementing number in a spreadsheet; if multiple people are using the spreadsheet at the same time and they don’t save it, there’s a potential for overwriting.
Auto number + Random
A lot of our clients use a combination of the auto number and random string as their obfuscated tracking code taxonomy to further ensure unique values.
Auto Append Date
Do you ever see a lot of traffic coming in from an old tracking code? Claravine’s automated Date variable enables you to automatically append the tracking codes’ created date anywhere within the tracking code – obfuscated or not. For some of our customers, it helps them see if a tracking code getting lots of traffic is from a current campaign or uploaded after.
Edit functionality
What does the ability to edit provide?
Drafting
A lot of the time, practitioners don’t have all the information about their campaign ahead of time, or multiple teams are involved in filling out appropriate information tied to a tracking code. The editing feature allows you to create the code and add values later. Additionally, you can save as a draft and share it with other team members to finish filling out the required fields before submitting and generating your tracking code. This method can help reduce time-to-campaign, go live quicker, and collaborate across teams, etc.
Historical Classifications
You may have an event where you run a campaign every year. Eventually, you may want your metadata taxonomy for the campaign SuperBowl2019 to change to Superbowl_2019. If you want your historical data to match the new underscore delimited structure (or other naming convention), the editing function will help, and retroactively update those values.
It’s also useful for correcting any errors. For example, if someone typed something incorrectly or put in the wrong list value, it’s easy to update.
Avoid Traditional (Tedious) Processes
Editing a delimiter or an upper case to a lower case to match the format in your analytics solution seems relatively simple. However, the two ways to manually upload classifications data (FTP Import or manual CSV import) become tedious quickly. Either method may include downloading hundreds of thousands of rows of data just to fix five lines of code. Despite that work, it’s still possible to miss errors without validation. Note: Manual import via a .csv file limits the number of rows you can upload at a time, so FTP is preferred for tasks like product classifications.
For anyone curious, a typical FTP process looks something like this:
- Go into Adobe Classification Importer
- Download a template with the correct header
- Double-check the values, select FTP Import
- Select correct FTP client
- Access the FTP server using client
- Upload the file as .tab or .txt
- Upload an empty FIN file when you’re ready to process
- Wait for data to be processed by Adobe to make sure you were successful
- Error? Repeat.
To illustrate, a colleague used to spend 10 hours a week fixing historical classifications manually via Adobe. The edit function has reduced that to 2 hours a week.
Tracking Code creator accountability
How do we know that tracking codes will be created successfully?
- The URL Validation functionality for the page and the Adobe/Google Analytics pixel placement makes sure important tracking components aren’t missed.
- Look for the green checkmark, so you know your tracking codes were processed (no FTP wait time)
Recommended format
Do we have a recommended format?
There are lots of considerations to make when deciding on the tracking code format and taxonomy that suits your team or organization best. You want to make sure that your tracking code structure (and the system creating them) remain consistent 100% of the time. We’d recommend you start to move towards using obfuscated tracking codes (don’t rely just on Rule Builder) and consider using Claravine to save time classifying your data.
If you’re ready to learn more about how Claravine helps, get started here.
