

Split & Extract: Your Swiss Army Knife of Data Standards
Whether you’re dealing with campaign data, naming conventions, or marketing taxonomies, the split & extract feature in The Data Standards Cloud® is your new best friend.
Take fields of data – imported into the platform as needed – then split apart the various components. As a part of this flow, you can convert coded dimensions into readable formats and make it easy to review, validate and correct values.
How? Well, the name is pretty self explanatory. This feature allows you to take a name – like a campaign name – and split apart the various short code elements.
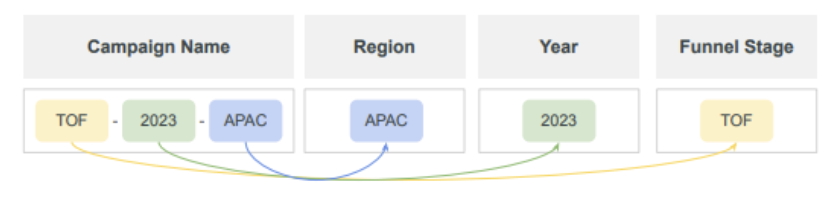
Once split apart, you can extract the coded elements and turn them into something more human readable to support your use case.
This may sound simple, but what it unlocks is anything but! While naming conventions are so key to a successful data strategy, they can be hard to maintain without a proper process.
For example, if you let your data creators put in any name into an open text field in a digital marketing campaign, you’d quickly end up with a data mess that complicates your ability to measure performance. That’s why it is vital that the elements and structure of a name are consistent. Because when you have a standard, you can easily compare across campaigns.
Additionally, but no less important, is the ability of standardized names to help with user productivity. When we have standardized names, users across teams can quickly search and browse and understand the information about a campaign even if they may not have set it up.
So, when you do naming right, not only can your teams speak the same data language, but you have the ability to encode metadata into your ID or your names with these short codes.
And when you use split and extract, you can quickly decode that metadata and make quick use of it.
Let’s discuss some of the ways this feature can help you elevate your data standards!
Validate Your Data: Performing a Data Health Check
Today, your media teams and agencies may be using a variety of naming conventions and processes to create campaigns. But it’s really hard to understand when data adheres to your standard or doesn’t because identifying errors and inconsistencies can be tricky. Not any more!
With split and extract you can do a health check on how well data is adhering to the taxonomy that you have in place without manually reviewing a list.
The process looks a bit like this:
- Concatenated data is added to the Claravine platform (this could be done directly in the UI, via File Import, or by using one of our inbound integrations)
- Data is split into individual parts based on delimiter
- The split data becomes visible in specified fields
- The platform automatically shows if data is valid.
- Yes? Data is submitted and saved to the dataset.
- No? The user can make a correction before adding data to the dataset.
For example, we had a customer that was looking to audit GCM campaign placements and creative names. We automatically imported their names into a template that was built with the correct values. We then parsed out the values, auto filling them into different columns and compared them against the defined template standard. Any errors were immediately highlighted, making it easy to see where an element was input incorrectly, or perhaps missed.
But this isn’t just about evaluating accuracy, it’s also about fixing it. Once the elements are split apart, the team can make any needed corrections to the specific elements with issues and can save the data and use it to generate a new, compliant name.
Finally, a world where 100% data compliance is a reality!
Convert Short Codes: Making Data Readable
It can be easy to forget that data isn’t just for crunching in some system, it’s also a vital part of your teams’ workflows. But when data is all short codes and abbreviations it can be incredibly hard for people to use it quickly or accurately.
This is why another great use case for split and extract is simply converting coded dimensions – or short code abbreviations – into human readable formats.
We know teams often set up naming conventions with codes to make their campaign name shorter and more manageable. Sometimes that’s a requirement of a certain system you’re using, or simply a team preference. But when people get creative and use abbreviations or codes to create shortened naming conventions, analytics solutions can struggle to decode and translate the metadata.
Many times we even see naming conventions within naming conventions. For example, one team might have their unique short code approach. And once they pass that campaign to the next team, more campaign details with more short codes are added leading to multiple layers of coded data, sometimes using different delimiters.
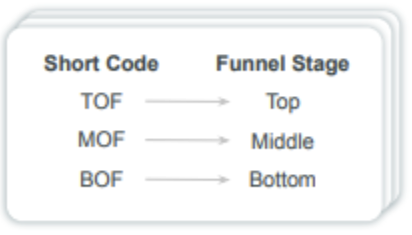
Here are a few of the types of naming conventions we see:

With split and extract, we can parse out those layered naming conventions as many times as needed to be able to turn them into a legible format.
So, if we have values separated by an underscore, and then there’s values within those values that are separated by a dash, we can split out their underscore values into their respective fields while at the same time splitting out the values separated by that dash!
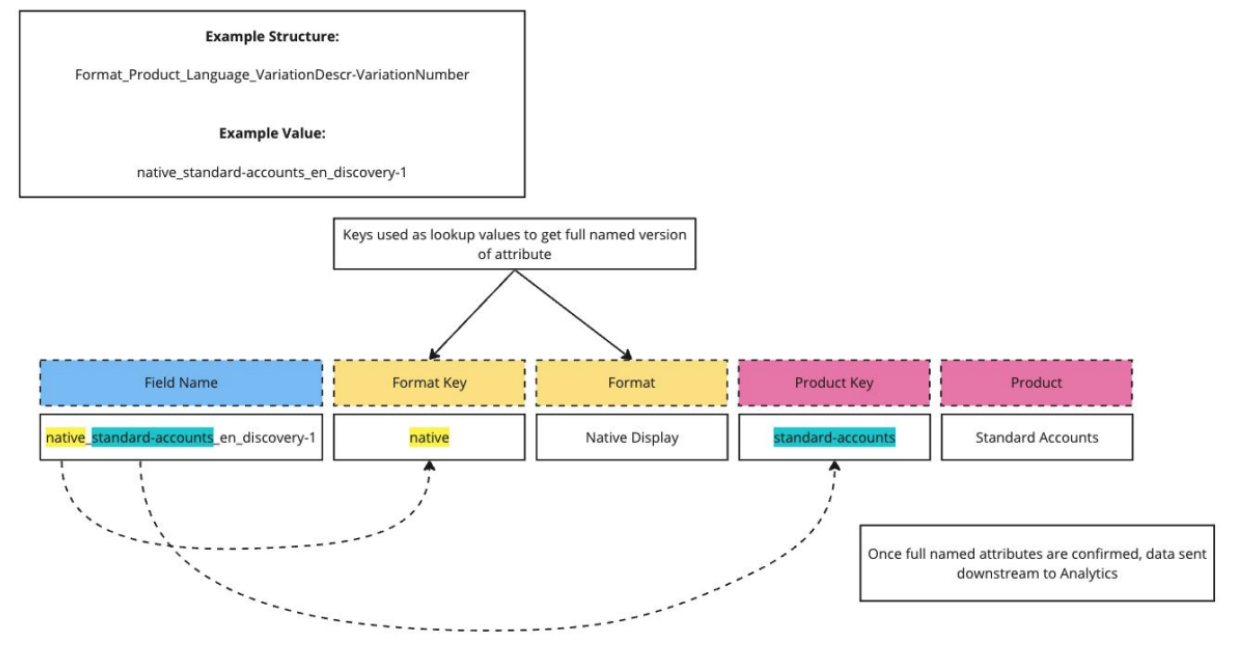
As you know, there’s advantages to using short codes. Split and extract ensures you can keep using them, but get more value from them across your systems.
Automation: Connecting Templates & Systems
Finally, let’s talk about using automation to make some of this work even easier.
First, let’s introduce you to the “power” of powered lists. This feature uses The Data Standard Cloud’s ability to have one saved list in one dataset fuel or “power” a list in another dataset. Why would you need this? Perhaps you are dealing with error prone reports stemming from teams’ reliance on copy & paste to share campaign names and metadata.
To mitigate this, you can power a list with specific values. This allows you to transform data by:
- Parsing out a specific element within a campaign name
- Saving extracted elements to a powered list
- Auto-populating metadata for the next team to select from
There are two paths when we bring in powered lists with split and extract:
- Saving extracted elements into a powered list to be used on another template. Perhaps you have a campaign name that includes things like geography, product channel, maybe a random ID, etc. We can parse out the product name or the geo and place those into a powered list to be used on another template, for another reason.
- Using powered lists to bring a set of metadata along the journey. (Let’s say we fill out another template, like a creative template first, and we have a unique ID associated with all of the metadata fields in that template. If we know that creative and it’s part of our full campaign, we can parse out that unique ID and have it be the first field in a powered list on our campaign template. When selected, this can essentially bring all of our creative metadata along with that creative, and we can send all of it downstream together, instead of sending data from two different templates.)
The other way you can automate work is by using media integrations!
You can use our platform’s various connectors to seamlessly bring in naming conventions and perform an audit. For example, you can connect a template to Meta Ads Manager, bring in naming conventions, split and extract them and drop them into pending for your team to pick up.
All they have to do is look at the data and see if there are any mistakes. If not – great! But if you catch something, this can be corrected before it starts a data mess.
You can also read a bit more about how this works with our Meta connector.
Remember, if you don’t want to connect directly to a media platform, you can still build a template and manually import or copy/paste campaign names, placement names, creative names, etc. into a template to perform your data health check. But we always love to help our customers automate a step in the process!
Customizations
Finally, when you are setting up split and extract, you have some options to customize it for each of your unique workflows, teams or technology set-ups.
These include:
- Standardized logic: configure automated logic on the field during setup
- Preset or Custom: split text on preset or custom delimiters
- Previews: opt to preview logic before saving
- Decode data: nest transformations together for complex naming conventions
- Automation: automatic extraction as data is entered or imported into the product, or exported back into a platform in instances where we have update capability
Curious about how this all looks in practice? You’re in luck. View a full demo in our Quick Vine webinar below.
What’s Next?
Are you interested in learning more about how this connector can help your team? If you are already a customer, reach out to your Claravine team or submit a support request. If you aren’t a customer, talk to our team today!